Французская компания Mistral выпустила в четверг новую модель синтеза речи с открытым исходным кодом, которая может быть использована голосовыми ИИ-помощниками или в корпоративных случаях, таких как поддержка клиентов. Модель, которая позволяет предприятиям создавать голосовых агентов для продаж и взаимодействия с клиентами, ставит Mistral в прямую конкуренцию с такими компаниями, как ElevenLabs, Deepgram и OpenAI.
Новая модель, называемая Voxtral TTS, поддерживает девять языков, включая английский, французский, немецкий, испанский, голландский, португальский, итальянский, хинди и арабский.
«Наши клиенты просили модель синтеза речи. Поэтому мы построили компактную модель речи, которая может работать на умных часах, смартфоне, ноутбуке или других устройствах на периферии сети. Её стоимость — это доля от любого другого решения на рынке, но она обеспечивает передовую производительность», — сказал Пьер Сток, вице-президент научных операций Mistral AI, в интервью TechCrunch.
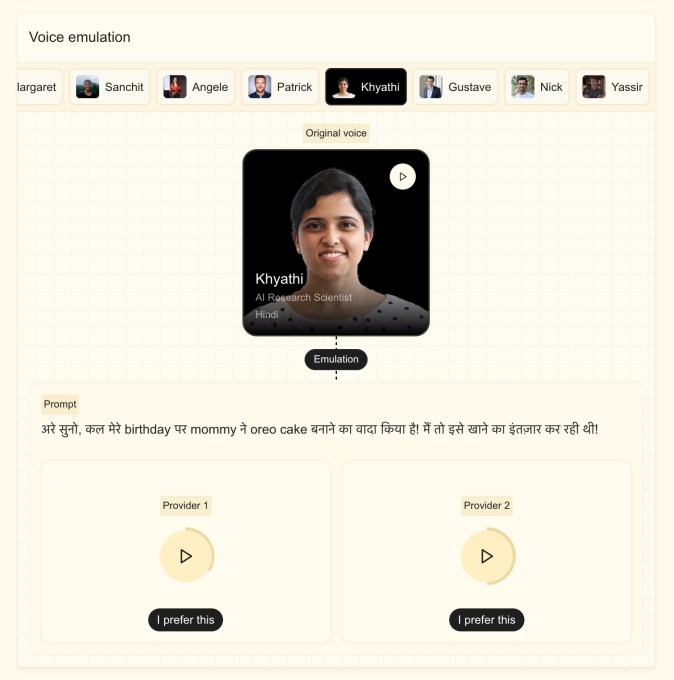
Mistral заявила, что новая модель может адаптировать пользовательский голос с образцом менее пяти секунд и может воспроизводить характеристики, такие как тонкие акценты, интонации, модуляции и нарушения в потоке речи. Модель, основанная на Ministral 3B, может легко переключаться между языками без потери характеристик голоса, что полезно для случаев, таких как дубляж или одновременный перевод. Сток сказал, что компания хотела, чтобы модель звучала человечески, а не робототехнично.
Модель была разработана для работы в реальном времени, согласно компании. Она имеет время до первого звука (TTFA) — показатель того, когда модель начинает «говорить» после получения входных данных — 90 мс для 10-секундного образца из 500 символов. Модель также имеет коэффициент реального времени (RTF) 6x, что означает, что она может отрендерить 10-секундный видеоклип примерно за 1,6 секунды.
В начале этого года Mistral запустила две модели транскрипции, одну для массовой обработки и другую для случаев использования в реальном времени с низкой задержкой. С новой моделью синтеза речи компания, вероятно, стремится предоставить полный набор голосовых продуктов для предприятий.
«Мы планируем создать комплексную платформу, которая может обрабатывать мультимодальные потоки входных данных, включая аудио, текст и изображение, а также выходные данные. Основное преимущество заключается в том, что вы получаете гораздо больше информации с помощью сквозной агентской системы, которая поддерживает аудио в качестве входных или выходных данных», — сказал Сток.
Позиционирование Mistral заключается в том, что её открытый исходный код и возможности настройки помогут предприятиям принять её модели синтеза речи перед конкурентами, поскольку они могут настраивать её так, как им хочется.