Когда модель начинает деградировать, типичный подход — одно из трёх: переобучение на новых помеченных данных, использование ансамбля с недавно обученной моделью или откат к предыдущей контрольной точке.
Все стандартные подходы предполагают наличие того, чего у вас может не быть:
- Помеченные данные
- Время на переобучение
- Контрольная точка, работающая на новом распределении
Откат особенно обманчив.
Откат к чистым весам на смещённом распределении не решает проблему — он повторяет её.
Я хотел создать что-то, что могло бы работать в промежутке: нет новых помеченных данных, нет простоев, нет отката к распределению, которое уже не существует. Это ограничение сформировало архитектуру.
Хотя этот эксперимент сосредоточен на обнаружении мошенничества, такое же ограничение появляется в любой производственной системе, где переобучение задерживается — в системах рекомендаций, оценке рисков, обнаружении аномалий или персонализации в реальном времени.
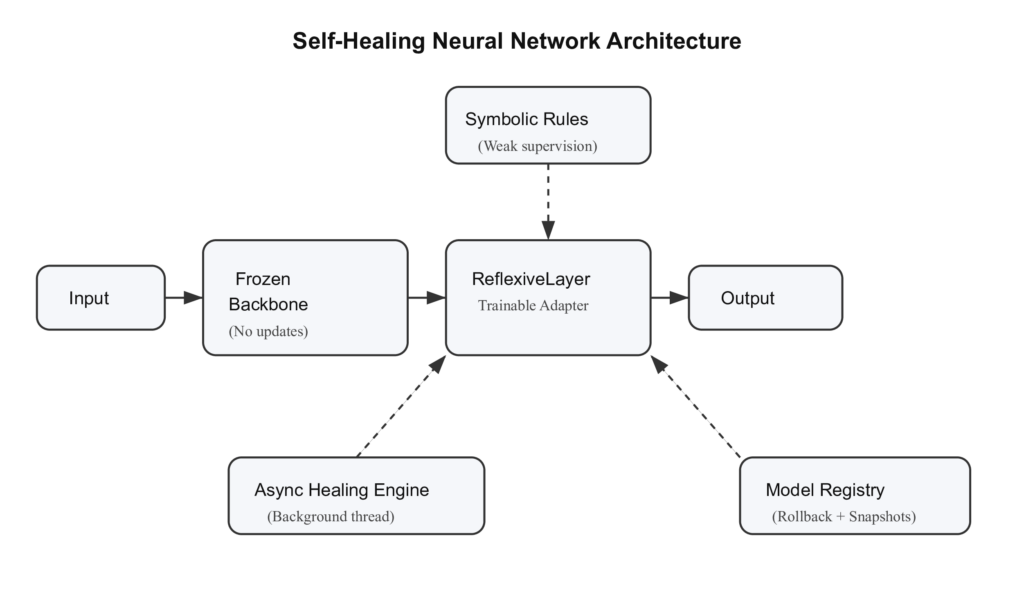
Архитектура: один замороженный костяк, один обучаемый адаптер
Ключевое проектное решение — где разместить обучаемую ёмкость. Вместо того чтобы сделать всю сеть адаптируемой, я изолирую адаптацию в одном компоненте — ReflexiveLayer, расположенном между замороженным костяком и замороженной выходной головой.
Вот архитектура одним взглядом:
class ReflexiveLayer(nn.Module):
def __init__(self, dim):
super().__init__()
self.adapter = nn.Sequential(
nn.Linear(dim, dim), nn.Tanh(),
nn.Linear(dim, dim)
)
self.scale = nn.Parameter(torch.tensor(0.1))
def forward(self, x):
return x + self.scale * self.adapter(x)Остаточное соединение (x + self.scale * self.adapter(x)) выполняет здесь важную работу. Параметр scale начинается с 0.1, поэтому адаптер изначально является почти нулевым возмущением. Сигнал костяка проходит почти без изменений. По мере накопления исправлений scale может расти, но исходный выход костяка всегда присутствует в сигнале. Адаптер может только добавлять коррекцию; он не может переписать то, что выучил костяк.
Адаптер не может переписать модель — он может только исправить её.
Полная модель встраивает ReflexiveLayer между костяком и выходной головой:
class SelfHealingMLP(nn.Module):
def __init__(self, input_dim=10, hidden_dim=64):
super().__init__()
self.backbone = nn.Sequential(
nn.Linear(input_dim, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim), nn.ReLU()
)
self.reflexive = ReflexiveLayer(hidden_dim)
self.output_head = nn.Sequential(
nn.Linear(hidden_dim, 1), nn.Sigmoid()
)
def freeze_for_healing(self):
for p in self.backbone.parameters():
p.requires_grad = False
for p in self.output_head.parameters():
p.requires_grad = False
def unfreeze_all(self):
for p in self.parameters():
p.requires_grad = TrueВо время события восстановления сначала вызывается freeze_for_healing(). Только ReflexiveLayer получает обновления градиентов. После восстановления unfreeze_all() восстанавливает полный граф параметров на случай, если в конечном итоге будет запущено полное переобучение.
Стоит отметить количество параметров: модель имеет 13 250 параметров всего, а ReflexiveLayer содержит 8 321 из них (два линейных слоя 64×64 плюс скалярный scale). Это 62,8% от всего объёма. Костяк, который отображает 10 входных признаков через 64 скрытых единицы в двух слоях, содержит всего 4 864. Таким образом, адаптер не является «маленьким» по количеству параметров. Он архитектурно сосредоточен: его задача ограничена преобразованием скрытых представлений костяка, и остаточное соединение плюс замороженный костяк гарантируют, что он не может разрушить то, что было выучено во время обучения.
Почему это разделение важно: катастрофическое забывание (тенденция нейронных сетей терять ранее выученное поведение при обновлении на новых данных) ограничено, потому что костяк всегда заморожен во время восстановления. Поток градиента во время шагов восстановления касается только адаптера, поэтому фундаментальные представления не могут деградировать независимо от того, сколько событий восстановления произойдёт.
Два сигнала, которые решают, когда восстанавливать
Восстановление, срабатывающее слишком часто, тратит вычисления впустую. Восстановление, срабатывающее слишком поздно, позволяет деградации накапливаться. Система использует два независимых сигнала.
Сигнал первый: FIDI (Feature-based Input Distribution Inspection)
FIDI отслеживает скользящее среднее признака V14, признака, который сеть независимо определила как свой самый сильный сигнал мошенничества. Она вычисляет z-оценку против статистики калибровки с обучения:
FIDI | μ=-0.363 σ=1.323 threshold=1.0
V14 clean | mean=-0.377 pct<-1.5 = 18.8%
V14 drift | mean=-2.261 pct<-1.5 = 77.4%
Когда z-оценка превышает 1.0, входящие данные больше не похожи на распределение обучения. В этом эксперименте z-оценка пересекает порог на пакете 3 и остаётся повышенной. Смещённое распределение V14 имеет среднее значение на 1,9 стандартного отклонения ниже калибровки, и это смещение применяется как постоянный сдвиг ко всем 25 пакетам. Система корректно его обнаруживает и никогда не возвращается в состояние HEALTHY.
Сигнал второй: символические конфликты
SymbolicRuleEngine кодирует одно доменное правило: если V14 < -1.5, транзакция, вероятно, является мошенничеством. Конфликт возникает, когда нейронная сеть назначает низкую вероятность мошенничества (ниже 0.30) транзакции, которую правило отмечает. Когда в пакете появляется пять или более конфликтов, восстановление срабатывает даже без значительного изменения z-оценки.
Два сигнала дополняют друг друга. FIDI чувствительна к смещению общего распределения в среднем V14. Подсчёт конфликтов чувствителен к несогласию модели с правилом на конкретных образцах и может поймать локальную деградацию, которую может пропустить z-оценка распределения. В датасете 15,0% мошенничества (150 транзакций мошенничества в тестовом наборе из 1000 образцов).
 %%END%%
%%END%%