Векторный взгляд на метод наименьших квадратов.
Мы думаем, что линейная регрессия — это подгонка линии под данные.
Но математически это совсем не то, что она делает.
Она находит ближайший возможный вектор к вашей целевой переменной в пространстве, натянутом на признаки.
Чтобы это понять, нам нужно изменить способ, которым мы смотрим на наши данные.
В части 1 мы получили базовое представление о том, что такое вектор, и исследовали концепции скалярного произведения и проекций.
Теперь давайте применим эти концепции для решения задачи линейной регрессии.
У нас есть эти данные.

Обычный способ: пространство признаков
Когда мы пытаемся разобраться в линейной регрессии, мы обычно начинаем с диаграммы рассеяния между независимой и зависимой переменными.
Каждая точка на этой диаграмме представляет один ряд данных. Затем мы пытаемся провести линию через эти точки с целью минимизировать сумму квадратов остатков.
Чтобы решить это математически, мы выписываем уравнение функции потерь и применяем дифференцирование, чтобы найти точные формулы для наклона и свободного члена.
Как мы уже обсуждали в моей предыдущей статье по множественной линейной регрессии (MLR), это стандартный способ понимания проблемы.
Это то, что мы называем пространством признаков.
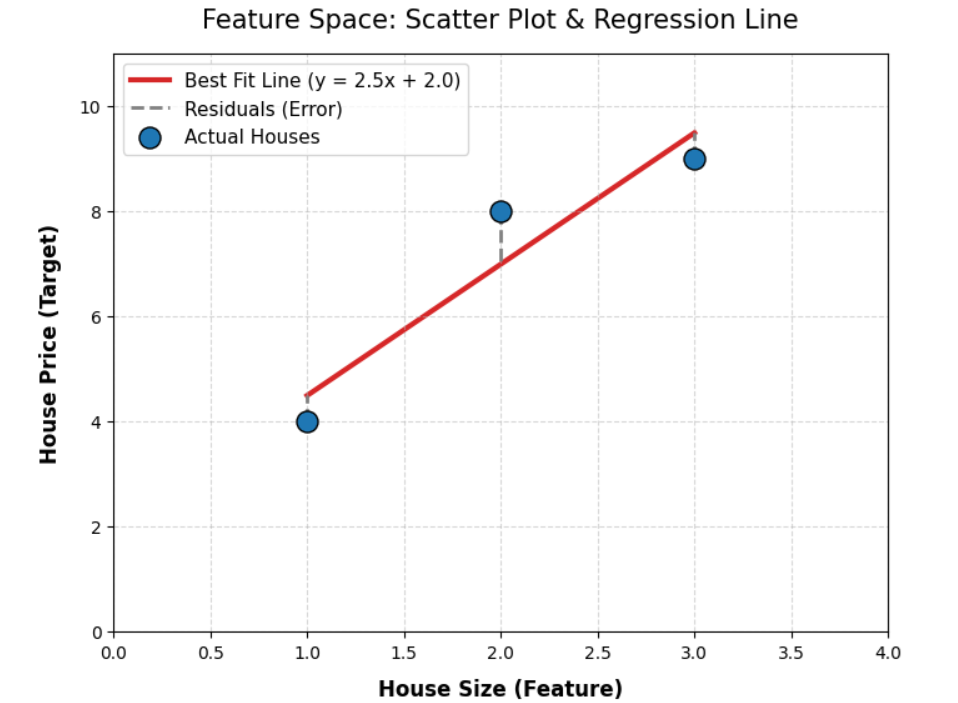
После выполнения всего этого процесса мы получаем значения для наклона и свободного члена. Здесь нам нужно заметить одну вещь.
Допустим, ŷᵢ — это предсказанное значение в определённой точке. У нас есть значения наклона и свободного члена, и теперь в соответствии с нашими данными нам нужно предсказать цену.
Если ŷᵢ — это предсказанная цена для дома 1, мы вычисляем её используя
β₀ + β₁ ⋅ размер
Что мы здесь сделали? У нас есть значение размера, и мы масштабируем его на определённое число, которое мы называем наклоном (β₁), чтобы получить значение как можно ближе к исходному значению.
Мы также добавляем свободный член (β₀) как базовое значение.
Теперь давайте запомним эту идею и перейдём к следующей перспективе.
Изменение перспективы
Давайте посмотрим на наши данные.
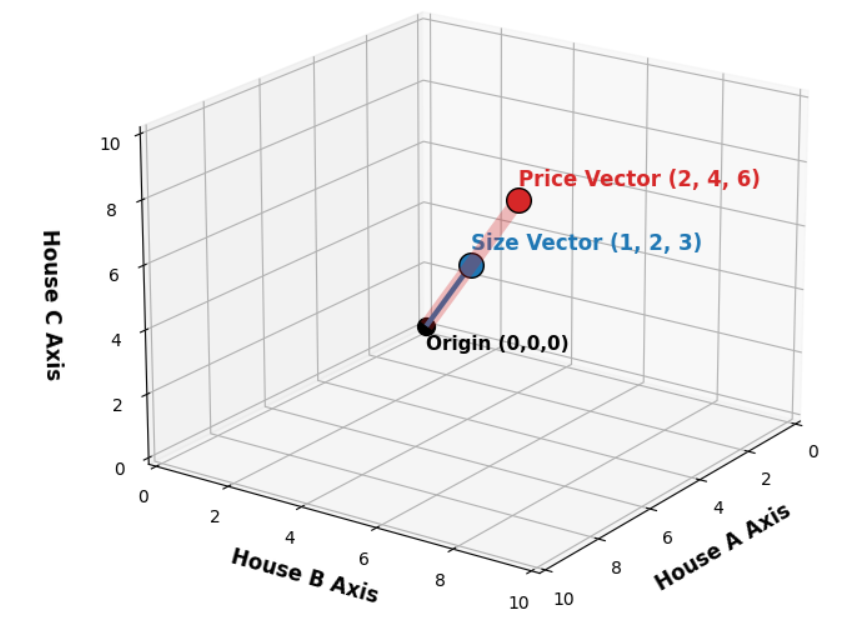
Теперь вместо того, чтобы рассматривать цену и размер как оси, давайте рассмотрим каждый дом как ось.
У нас есть три дома, что означает, что мы можем рассматривать дом A как ось X, дом B как ось Y и дом C как ось Z.
Затем мы просто строим наши точки.
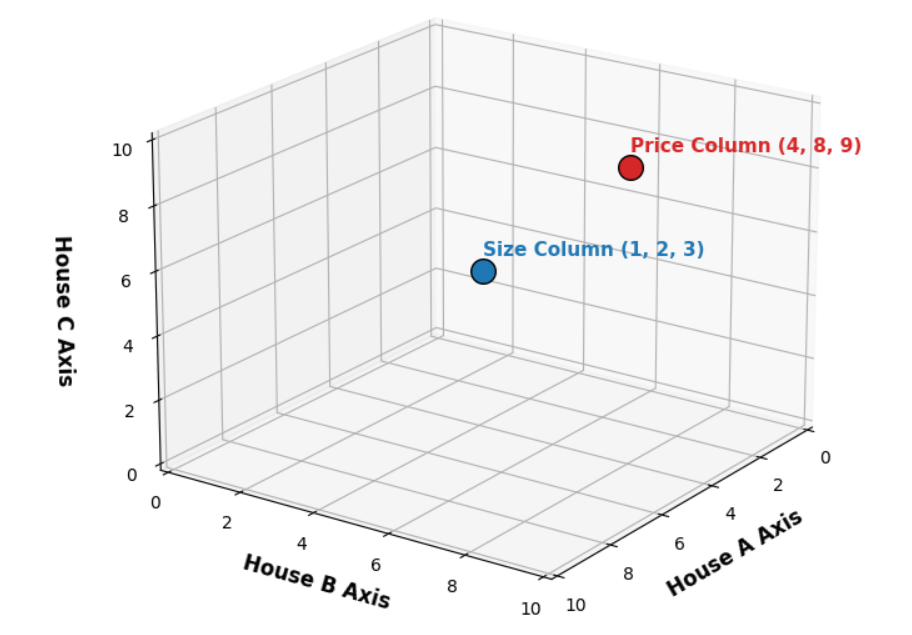
Когда мы рассматриваем столбцы размер и цена как оси, мы получаем три точки, где каждая точка представляет размер и цену одного дома.
Однако когда мы рассматриваем каждый дом как ось, мы получаем две точки в трёхмерном пространстве.
Одна точка представляет размеры всех трёх домов, а другая точка представляет цены всех трёх домов.
Это то, что мы называем пространством столбцов, и именно здесь происходит линейная регрессия.
От точек к направлениям
Теперь давайте соединим наши две точки с началом координат и назовём их векторами.
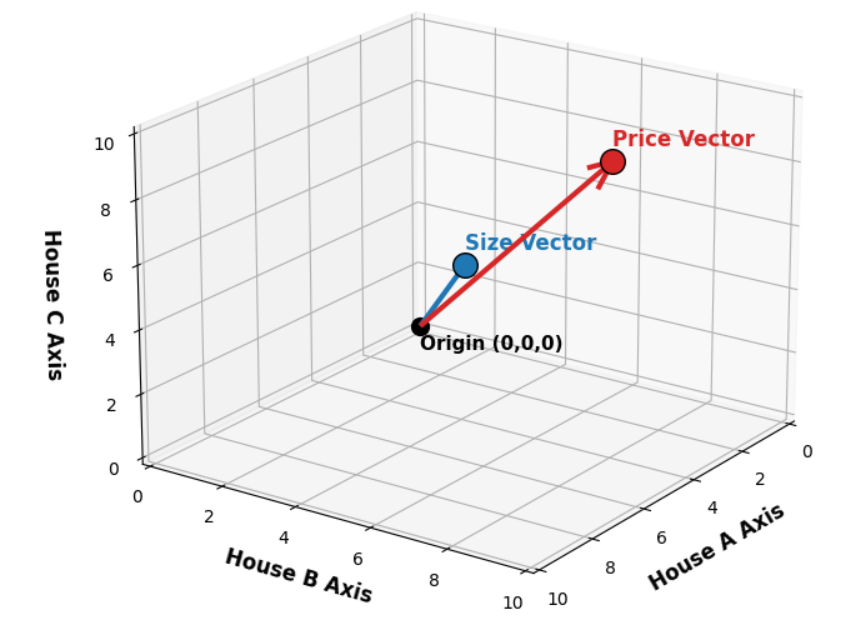
Хорошо, давайте помедленнее и посмотрим, что мы сделали и почему мы это сделали.
Вместо обычной диаграммы рассеяния, где размер и цена являются осями (пространство признаков), мы рассматривали каждый дом как ось и строили точки (пространство столбцов).
Мы теперь говорим, что линейная регрессия происходит в этом пространстве столбцов.
Вы можете подумать: подождите, мы изучаем и понимаем линейную регрессию, используя традиционную диаграмму рассеяния, где мы минимизируем остатки, чтобы найти лучшую линию.
Да, это верно! Но в пространстве признаков линейная регрессия решается с использованием исчисления. Мы получаем формулы для наклона и свободного члена, используя частное дифференцирование.
Если вы помните мою предыдущую статью о MLR, мы вывели формулы для наклонов и свободных членов, когда у нас было два признака и целевая переменная.
Вы можете заметить, как беспорядочно было рассчитывать эти формулы с помощью исчисления. Теперь представьте, что у вас есть 50 или 100 признаков; это становится сложным.
Переходя на пространство столбцов, мы меняем линзу, через которую мы смотрим на регрессию.
Мы смотрим на наши данные как на векторы и используем концепцию проекций. Геометрия остаётся ровно такой же, независимо от того, имеем ли мы 2 признака или 2000 признаков.
Итак, если исчисление становится таким беспорядочным, в чём реальное преимущество этой неизменной геометрии? Давайте обсудим ровно то, что происходит в пространстве столбцов.
Почему эта перспектива важна
Теперь, когда у нас есть представление о том, что такое пространство признаков и пространство столбцов, давайте сосредоточимся на графике.
У нас есть две точки: одна представляет размеры, а другая представляет цены домов.
Почему мы соединили их с началом координат и рассматривали их как векторы?
Потому что, как мы уже обсуждали, в линейной регрессии мы находим число (которое мы называем наклоном или весом), чтобы масштабировать нашу независимую переменную.
Мы хотим масштабировать размер так, чтобы он приблизился к цене, минимизируя остаток.
Вы не можете визуально масштабировать число с плавающей точкой; вы можете масштабировать что-то только когда оно имеет длину и направление.
Соединяя точки с началом координат, они становятся векторами. Теперь у них есть как величина, так и направление, и мы уже знаем, что мы можем масштабировать векторы.
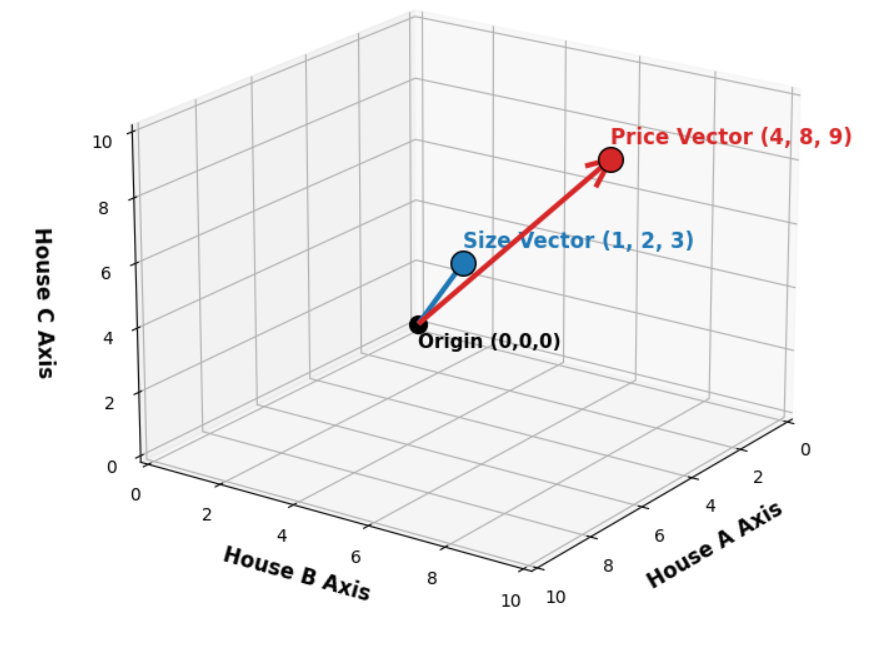
Хорошо, мы установили, что мы рассматриваем эти столбцы как векторы, потому что мы можем их масштабировать, но есть кое-что ещё более важное, что нужно здесь понять.
Давайте посмотрим на наши два вектора: вектор размера и вектор цены.
Сначала, если мы посмотрим на вектор размера (1, 2, 3), он указывает в очень специфическом направлении на основе паттерна его чисел.
Из этого вектора мы можем понять, что дом 2 в два раза больше, чем дом 1, а дом 3 в три раза больше.
Существует определённое соотношение 1:2:3, которое заставляет вектор размера указывать в одном точном направлении.
Теперь, если мы посмотрим на вектор цены, мы можем увидеть, что он указывает в немного другом направлении, чем вектор размера, на основе своих собственных чисел.
Направление стрелки просто показывает нам чистый, базовый паттерн признака во всех наших домах.
Если бы наши цены были точно (2, 4, 6), то наш вектор цены лежал бы ровно в одном направлении с нашим вектором размера. Это означало бы, что размер является идеальным, прямым предсказателем цены.
Но в реальной жизни это редко возможно. Цена дома зависит не только от размера; на неё влияют различные другие факторы, поэтому вектор цены указывает немного в сторону.
Угол между двумя векторами (1,2,3) и (4,8,9) представляет шум в реальном мире.
Геометрия регрессии
Теперь мы используем концепцию проекций, которую мы изучили в части 1.
Давайте рассмотрим наш вектор цены (4, 8, 9) как место назначения, которого мы хотим достичь. Однако у нас есть только одно направление, в котором мы можем двигаться, — это путь нашего вектора размера (1, 2, 3).
Если мы движемся в направлении вектора размера, мы не можем идеально достичь нашего пункта назначения, потому что он указывает в другом направлении.
Но мы можем доехать до определённой точки на нашем пути, которая приближает нас как можно ближе к пункту назначения.
Кратчайший путь от нашего пункта назначения, опускающийся вниз в эту точку, составляет идеальный угол 90 градусов.
В части 1 мы обсуждали эту концепцию, используя аналогию «шоссе и дом».
Мы применяем здесь ровно такую же концепцию. Единственное различие состоит в том, что в части 1 мы были в двумерном пространстве, а здесь мы находимся в трёхмерном пространстве.
Я назвал признак «путём» или «шоссе», потому что у нас есть только одно направление движения.
Это различие между «путём» и «направлением» станет намного яснее позже, когда мы добавим несколько направлений!
Простой способ увидеть это
Мы уже можем заметить, что это ровно та же концепция, что и проекции векторов.
Мы вывели формулу для этого в части 1. Так почему бы не применить её?
Нет. Ещё не время.
Есть кое-что важное, которое мы должны понять сначала.
В части 1 мы имели дело с двумерным пространством, поэтому мы использовали аналогию «шоссе и дом». Но здесь мы находимся в трёхмерном пространстве.
Чтобы лучше это понять, давайте используем новую аналогию.
Представьте это трёхмерное пространство как физическую комнату. В комнате плывёт лампочка с координатами (4, 8, 9).
Путь от