Постоянная память ИИ без embeddings, Pinecone или докторской степени в поиске подобия.

Всё началось с того, что мой помощник Obsidian постоянно забывал информацию. Я не хотел развёртывать Pinecone или Redis только для того, чтобы Claude помнил, что Алиса утвердила бюджет Q3 на прошлой неделе. Оказывается, с контекстным окном в 200K+ токенов вам может вообще не понадобиться ничего из этого.
Я хочу поделиться новым механизмом, который я начал использовать. Это система, построенная на SQLite и прямом рассуждении LLM, без векторных баз данных, без pipeline эмбеддингов. Векторный поиск был в основном обходным решением для крошечных контекстных окон и защиты промптов от беспорядка. С современными размерами контекста вы часто можете пропустить это и просто позволить модели напрямую читать ваши воспоминания.
Подготовка
Я делаю подробные заметки, как в личной жизни, так и на работе. Раньше я писал в тетради, которые теряли, или они валялись на полке и больше никогда не открывались. Несколько лет назад я перешёл на Obsidian для всего, и это было фантастически. В последний год я начал подключать генеративный ИИ к своим заметкам. Сегодня я использую Claude Code (для личных заметок) и Kiro-CLI (для рабочих заметок). Я могу задавать вопросы, получать сводки для руководства, отслеживать цели и писать отчёты. Но у этого всегда была одна большая уязвимость: память. Когда я спрашиваю о встрече, система использует Obsidian MCP для поиска в моём хранилище. Это занимает время, ненадёжно, и мне нужно, чтобы это было лучше.
Очевидное решение — векторная база данных. Встроить воспоминания. Сохранить векторы. Выполнить поиск подобия во время запроса. Это работает. Но это также означает Redis stack, аккаунт Pinecone или локально работающий экземпляр Chroma, плюс API для эмбеддингов, плюс код pipeline для всего этого. Для личного инструмента это многовато, и есть реальный риск, что это не будет работать ровно так, как мне нужно. Мне нужно спрашивать: «Что произошло 1 февраля 2026?» или «Подведи итоги последней встречи с этим человеком» — то, с чем эмбеддинги и RAG плохо справляются.
Затем я наткнулся на Google Memory Agent, всегда включённый. Идея довольно простая: вообще не делать поиск подобия; просто дайте LLM ваши недавние воспоминания и позвольте ему рассуждать над ними.
Я хотел узнать, будет ли это работать на AWS Bedrock с Claude Haiku 4.5. Поэтому я это построил (вместе с Claude Code, конечно) и добавил дополнительные украшения.
Посетите мой репозиторий GitHub, но обязательно вернитесь!
Идея, которая меняет математику
Старые модели максимум достигали 4K или 8K токенов. Вы не могли поместить в промпт больше нескольких документов. Эмбеддинги позволяли вам извлекать релевантные документы без загрузки всего. Это было действительно необходимо. Haiku 4.5 предлагает контекстное окно в 250K, так что мы можем сделать с этим?
Структурированное воспоминание (сводка, сущности, темы, оценка важности) занимает около 300 токенов. Это означает, что мы можем получить около 650 воспоминаний, прежде чем достичь потолка. На практике это немного меньше, поскольку системный промпт и запрос также потребляют токены, но для личного помощника, который отслеживает встречи, заметки и разговоры, это месяцы контекста.
Никаких эмбеддингов, никаких векторных индексов, никакого косинусного подобия.
LLM рассуждает напрямую о семантике, и он лучше в этом, чем косинусное подобие.
Архитектура
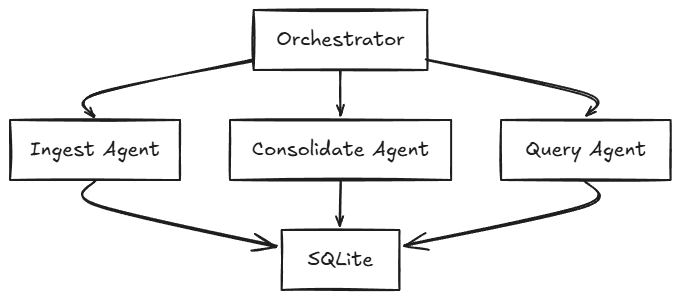
Оркестратор не является отдельным сервисом. Это класс Python внутри процесса FastAPI, который координирует трёх агентов.
Работа IngestAgent проста: возьмите сырой текст и попросите Haiku понять, что стоит помнить. Он извлекает сводку, сущности (имена, места, вещи), темы и оценку важности от 0 до 1. Этот пакет попадает в таблицу `memories`.
ConsolidateAgent работает с интеллектуальным планированием: при запуске, если существуют какие-либо воспоминания, когда достигнут порог (5+ воспоминаний по умолчанию), и ежедневно как обязательный проход. При срабатывании он объединяет несоединённые воспоминания и просит Haiku найти перекрёстные связи и сгенерировать инсайты. Результаты попадают в таблицу `consolidations`. Система отслеживает последнюю временную метку консолидации, чтобы обеспечить регулярную обработку даже при низком накоплении воспоминаний.
QueryAgent считывает недавние воспоминания плюс инсайты консолидации в один промпт и возвращает синтезированный ответ с идентификаторами цитирования. Это весь путь запроса.
Что на самом деле хранится
Когда вы добавляете текст типа «Встретился с Алисой сегодня. Бюджет Q3 одобрен, $2.4M», система не просто сбрасывает эту сырую строку в базу данных. Вместо этого IngestAgent отправляет его в Haiku и спрашивает: «Что здесь важно?»
LLM извлекает структурированные метаданные:
{
"id": "a3f1c9d2-...",
"summary": "Alice confirmed Q3 budget approval of $2.4M",
"entities": ["Alice", "Q3 budget"],
"topics": ["finance", "meetings"],
"importance": 0.82,
"source": "notes",
"timestamp": "2026-03-27T14:23:15.123456+00:00",
"consolidated": 0
}Таблица memories содержит эти отдельные записи. При ~300 токенах на воспоминание при форматировании в промпт (включая метаданные), теоретический потолок составляет около 650 воспоминаний в контекстном окне Haiku в 200K. Я намеренно установил по умолчанию 50 недавних воспоминаний, так что я намного ниже этого потолка.
Когда ConsolidateAgent запускается, он не просто суммирует воспоминания. Он рассуждает над ними. Он находит паттерны, устанавливает связи и генерирует инсайты о том, что воспоминания означают вместе. Эти инсайты хранятся как отдельные записи в таблице consolidations:
{
"id": "3c765a26-...",
"memory_ids": ["a3f1c9d2-...", "b7e4f8a1-...", "c9d2e5b3-..."],
"connections": "All three meetings with Alice mentioned budget concerns...",
"insights": "Budget oversight appears to be a recurring priority...",
"timestamp": "2026-03-27T14:28:00.000000+00:00"
}Когда вы выполняете запрос, система загружает как сырые воспоминания, так и инсайты консолидации в один промпт. LLM рассуждает над обоими слоями одновременно, включая недавние факты плюс синтезированные паттерны. Вот как вы получаете ответы типа «Алиса высказала озабоченность по поводу бюджета на трёх отдельных встречах [memory:a3f1c9d2, memory:b7e4f8a1] и паттерн предполагает, что это высокий приоритет [consolidation:3c765a26]».
Этот двухтабличный дизайн — это весь уровень персистентности. Один файл SQLite. Никакого Redis. Никакого Pinecone. Никакого pipeline эмбеддингов. Просто структурированные записи, которые LLM может напрямую анализировать.
Что на самом деле делает Consolidation Agent
Большинство систем памяти чисто поисковые. Они хранят, ищут и возвращают подобный текст. Consolidation Agent работает по-другому; Он считывает партию несоединённых воспоминаний и спрашивает: «Что их соединяет?», «Что общего в этих воспоминаниях?», «Как они связаны?»
Эти инсайты записываются как отдельная запись consolidations. Когда вы запрашиваете, вы получаете как сырые воспоминания, так и синтезированные инсайты. Агент не просто вспоминает. Он рассуждает.
Аналогия спящего мозга из оригинальной реализации Google кажется довольно точной. В часы простоя система обрабатывает информацию, а не просто ждёт. Это то, с чем я часто борюсь при построении агентов: как сделать их более автономными, чтобы они могли работать, когда я не работаю, и это хороший способ использовать это «простой».
Для личного инструмента это имеет значение. «Вы встречались с Алисой три раза в этом месяце, и все они упоминали озабоченность по поводу бюджета» более полезно, чем три отдельных хита воспоминания.
Оригинальный дизайн использовал простой порог для консолидации: он ждал 5 воспоминаний перед консолидацией. Это работает для активного использования. Но если вы добавляете спорадически, заметку здесь, изображение там, вы можете ждать дни перед тем, как достичь порога. Между тем, эти воспоминания лежат необработанными, и запросы не получают преимущества распознавания паттернов агента консолидации.
Поэтому я решил добавить два дополнительных триггера. Когда сервер запускается, он проверяет несоединённые воспоминания из предыдущей сессии и обрабатывает их сразу. Никакого ожидания. И на ежедневном таймере (настраиваемом) он форсирует пропуск консолидации, если что-то ожидает, независимо от того, был ли достигнут порог в 5 воспоминаний. Поэтому даже одна заметка в неделю всё равно будет консолидирована в течение 24 часов.
Оригинальный режим на основе порога по-прежнему работает для активного использования. Но теперь снизу есть сеть безопасности. Если вы активно добавляете, порог его ловит. Если нет, ежедневный пропуск его ловит. И при перезагрузке ничто не падает.