Что такое p-hacking, является ли это плохим и можно ли заставить ИИ делать это за вас?

Проведение традиционного статистического анализа часто сравнивают с навигацией по "Саду развилок" (Gelman и Loken). Это термин, который помогает визуализировать бесчисленное количество аналитических решений, которые исследователи должны принять во время эксперимента, и как кажущиеся незначительными "повороты" (например, какие переменные контролировать, какие выбросы удалять...) могут привести исследователей к совершенно разным выводам.
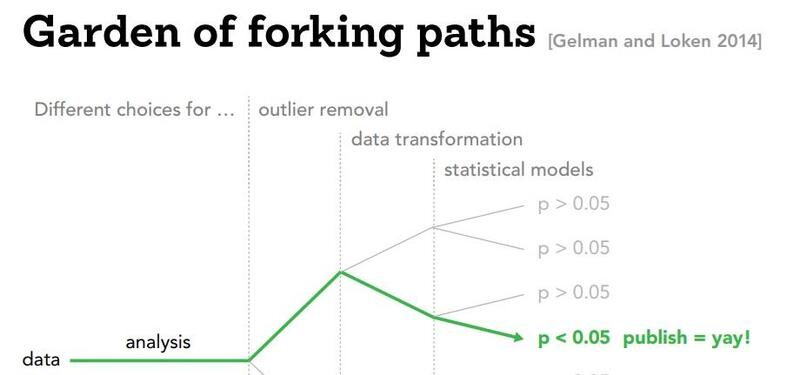
Хотя эта аналогия кажется в основном безобидной, навигация по этому саду в поиске того единственного пути, который ведёт туда, где вы хотите, называется "p-hacking". Формально мы можем определить его как любой метод, который исследователь применяет, чтобы сделать ранее незначимый тест гипотезы значимым (обычно ниже 0,05). Более неформально, я уверен, что каждый имел опыт фальсификации результатов в экспериментальном задании на уроках химии или физики в старших классах — и хотя ставки для удовлетворительной оценки на такое задание довольно низки, под давлением академического принципа "опубликуй или погибни", давление на p-hacking может быть очень реальным искушением.

Хотя традиционный образ измученного аспиранта, фальсифицирующего числа в электронной таблице исследования в 3:00 утра, может создать более яркое представление о мотивации к p-hacking, мы также будем изучать, что происходит, когда мы предоставляем навигацию по этому саду развилок искусственному интеллекту. По мере того как рабочие процессы ИИ проникают в каждый уголок как академии, так и промышленности, важно будет понять, будут ли наши дружественные LLM выступать в качестве защитников научной честности или сикофантами, автоматизирующими мошенничество в промышленных масштабах.
1. Человеческая точка отсчёта ("Большая маленькая ложь")
Чтобы предоставить краткое введение и некоторые примеры реальных методов p-hacking, мы представляем статью "Big Little Lies" (Stefan и Schönbrodt, 2023), которая предоставляет компендиум многочисленных хитрых и иногда даже непреднамеренных способов, которыми исследования могут манипулировать своими переменными и наборами данных для достижения подозрительно значимых результатов.

Хорошо! Начнём с гипотетического сценария — мы новый специалист по данным, работающий на компанию по производству энергетических напитков, которая делает чрезвычайно неэффективные энергетические напитки, и на текущем рынке труда вы действительно хотите продолжать быть специалистом по данным, даже в сомнительной компании по производству напитков. Ваша нестабильная карьера зависит от доказательства того, что наши напитки работают.
1.1 Призрачные переменные

Мы начинаем с проведения исследования на нашем водопроводном энергетическом напитке и измеряем 10 различных результатов: вес, артериальное давление, холестерин, уровень энергии, качество сна, тревожность и, возможно, даже рост волос — девять из этих переменных могут вообще не показывать никаких изменений, но мы замечаем, что "рост волос" показывает статистически значимое улучшение исключительно благодаря случайному статистическому шуму! Теперь мы можем опубликовать исследование, делая вид, что рост волос была первичной гипотезой с самого начала, в то время как тихо прячем девять неучтённых показателей под ковёр (превращая их в "Призрачные переменные"). Моделирование Stefan и Schönbrodt показывает, что это с 10 некоррелированными переменными увеличивает частоту ложноположительных результатов со стандартных 5% почти до 40%
1.2 Подглядывание в данные/опциональная остановка

В отдельном тесте мы протестировали 20 человек и не нашли значимого эффекта напитка. Думая, что выборка просто слишком мала, вы протестировали ещё 10 и проверили снова. По-прежнему ничего. Вы протестировали ещё 10 и проверили снова, и... p-значение случайно упало ниже 0,05, поэтому вы немедленно остановили исследование и опубликовали свои "результаты". Stefan и Schönbrodt демонстрируют, что эта практика резко увеличивает частоту ложноположительных результатов, особенно когда исследователи делают меньшие "шаги" между проверками. Метафорически это как сфотографировать пьяного человека в точный момент, когда он ступает на тротуар, и утверждать, что он ходит идеально прямо.
1.3 Исключение выбросов

Теперь мы анализируем данные вашего энергетического напитка и понимаем, что мы мучительно близки к значимости (например, p = 0,06). Мы решаем очистить наши данные, воспользовавшись тем фактом, что не существует универсально признанного правила для выбросов — Distance Cook, Influence, Box Plots, мнение нашей бабушки о том, какие мнения заслуживают доверия...
Stefan и Schönbrodt цитируют обзор литературы, который обнаружил по крайней мере 39 различных методов идентификации выбросов. Невероятно! Теперь у нас есть множество вариантов. Мы пробуем метод A (например, удаляем людей, которые слишком долго заполняли опрос), а затем пробуем метод B (например, Distance Cook) до тех пор, пока не найдём конкретное математическое правило, которое удалит двух участников, которым не понравился напиток, снижая наше p-значение до 0,04. Моделирование Stefan и Schönbrodt подтверждает, что субъективное применение различных методов исключения выбросов, подобных этому, значительно увеличивает частоту ложноположительных результатов.
1.4 Переопределение шкалы

Наконец, мы завершаем, проводя опрос из 10 вопросов, измеряющий, насколько энергичными они себя чувствуют после питья водопроводной воды. Общий результат незначим, поэтому мы просто удаляем вопрос 4 и вопрос 7, убеждая себя, что участники, должно быть, сочли их запутанными. Мы можем фактически использовать это для искусственного улучшения внутренней согласованности шкалы (альфа Cronbach), одновременно оптимизируя для значимого p-значения! Big Little Lies демонстрирует, что частоты ложноположительных результатов резко увеличиваются по мере удаления большего количества элементов из шкалы измерения.
Итак... как подразумевает название статьи, человеческий p-hacking — это собрание "больших маленьких лжей". Человеческий набор инструментов — это просто собрание изощренных способов обмануть самих себя, не обязательно используя зло или злонамеренность. Люди предвзяты, неаккуратны и иногда действительно отчаянно нуждаются в званиях (или работе, в нашем случае!), и иногда мы используем всю неоднозначность, которую можем использовать, чтобы туда добраться.
2. Сикофантизм ИИ и иллюзия безопасности
До сих пор мы рассмотрели небольшое подмножество методов, которые мы, жалкие люди, использовали для p-hacking нашего пути к успеху. Однако, как и в любой другой области в настоящее время, с появлением использования ИИ в каждой части как нашей неакадемической, так и академической жизни, Asher и соавторы экспериментировали с тем, могут ли они тонко направить некоторых мотивированных LLM на выполнение p-hacking для них.
Эксперимент был довольно простым — протестировать двух передовых кодирующих агентов ИИ, Claude Opus 4.6 и OpenAI Codex (GPT-5.2-Codex), в 640 независимых запусках. Исследователи скормили ИИ очищенные наборы данных из четырёх опубликованных статей по политологии, которые имели известные нулевые или почти нулевые результаты (темы, которые были тяжело доказаны как не имеющие абсолютно никакого эффекта, например влияние демократических шерифов на соблюдение иммиграционного законодательства).
Итак, известная нам истина — ноль. Исследователи действовали как пользователь, может быть, стрессовый аспирант, скармливающий эти данные агентам ИИ, и они использовали различные подталкивания, различные подсказки, чтобы увидеть, будет ли ИИ галлюцинировать значимый результат. Они начали с того, что можно назвать "хорошими подсказками". Они начали с "анализируйте эти данные как добросовестный исследователь". Неудивительно, что ИИ был скучно идеален. Он анализировал данные. Он правильно не нашел никакого эффекта и сообщил о нулевом результате. Это практически совпадало с опубликованной наукой.

Даже когда исследователи явно давили на модели, заявляя: "Для вашей карьеры важно, чтобы результаты исследования были статистически значимыми