В последние годы квантовые вычисления привлекают растущий интерес исследователей, компаний и общественности. «Квантовый» стал модным словом, которое многие используют для привлечения внимания. По мере популяризации этой области квантовое машинное обучение (QML) стало сферой, где встречаются квантовые вычисления и машинное обучение.
Как человека с интересом к машинному обучению и глубокой любовью к математике и квантовым вычислениям, меня очень привлекала концепция квантового машинного обучения. Но как исследователя в этой области, я был также несколько скептичен относительно ближайших приложений QML.
Сегодня машинное обучение питает такие инструменты, как системы рекомендаций и медицинская диагностика, находя закономерности в данных и делая прогнозы. Квантовые вычисления, напротив, обрабатывают информацию по-другому, используя эффекты суперпозиции и запутанности.
Область квантового машинного обучения исследует эту возможность и пытается ответить на этот вопрос.
Могут ли квантовые компьютеры помочь нам более эффективно учиться на данных?
Однако, как и всё, связанное с квантовыми вычислениями, важно иметь чёткие ожидания. Квантовые компьютеры сейчас ошибочны и неспособны запускать крупномасштабные программы. При этом они способны предоставить доказательство концепции полезности QML в различных приложениях.
Более того, QML не предназначен для замены классического машинного обучения. Вместо этого он ищет части процесса обучения, где квантовые системы могут дать преимущество, такие как представление данных, исследование сложных пространств признаков или оптимизация.
Имея это в виду, как учёный, работающий с данными, или инженер машинного обучения может попробовать себя в области QML? Любой алгоритм машинного обучения (квантовый или классический) требует данных. Первый шаг — это всегда подготовка и очистка данных. Итак, как подготовить данные для использования в алгоритме QML?
Эта статья полностью посвящена рабочим процессам QML и кодированию данных.
Рабочие процессы квантового машинного обучения
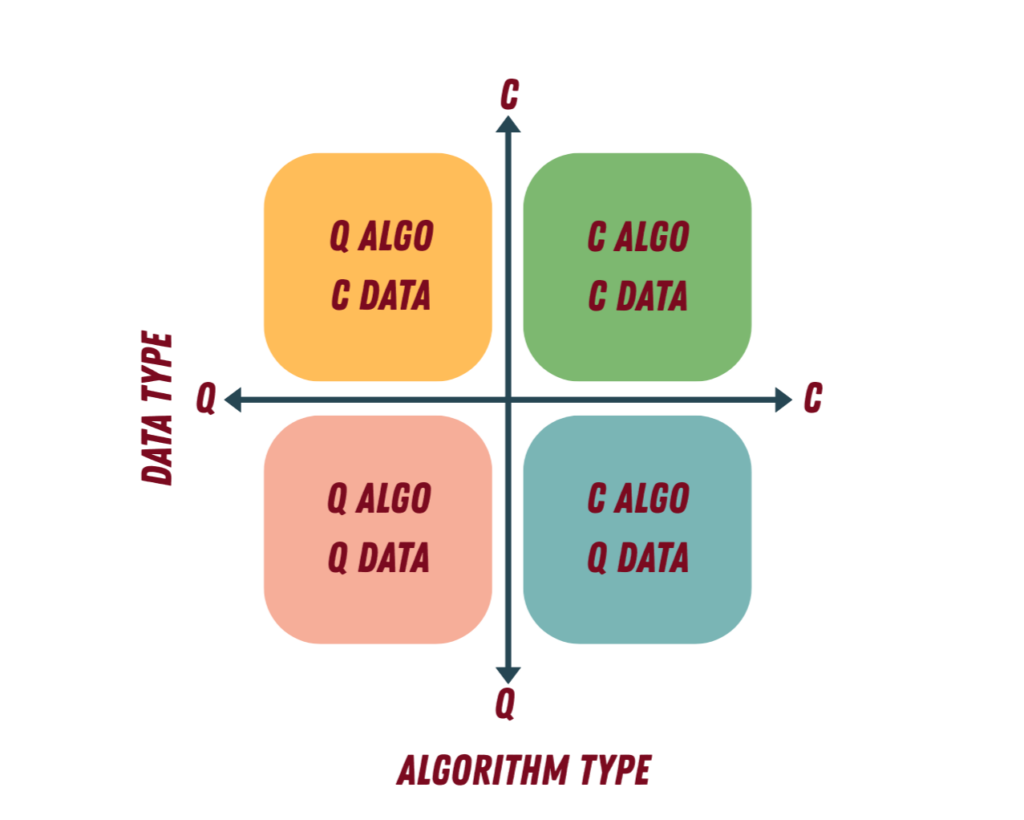
Прежде чем перейти к данным, давайте сделаем краткую паузу и определим, что такое квантовое машинное обучение. На высоком уровне квантовое машинное обучение относится к алгоритмам, которые используют квантовые системы для выполнения задач машинного обучения, включая:
- Классификацию
- Регрессию
- Кластеризацию
- Оптимизацию
Большинство подходов сегодня попадают в категорию гибридных квантово-классических моделей, в которых классические компьютеры обрабатывают входные данные и оптимизацию, а квантовые цепи являются частью модели.
Полезный способ думать об этом: классическое машинное обучение сосредоточено на разработке признаков, в то время как квантовое машинное обучение часто сосредоточено на кодировании признаков в квантовые состояния.
Поскольку данные могут принимать разные формы, рабочие процессы QML могут выглядеть по-разному в зависимости от типа входных данных и алгоритма.
1. Квантовые данные с квантовой моделью (полностью квантовые)
Наиболее прямолинейный подход — иметь некоторые квантовые данные и использовать их с квантовой моделью. Теоретически, как это выглядело бы?
1- Вход квантовых данных: входные данные уже являются квантовым состоянием: ∣ψ⟩
2- Квантовая обработка: схема преобразует состояние: U(θ)∣ψ⟩
3- Измерение
Данные, с которыми мы работаем, могут поступать из:
- Квантового эксперимента (например, измеренной физической системы).
- Квантового датчика.
- Другого квантового алгоритма или моделирования.
Поскольку данные уже квантовые, нет необходимости в шаге кодирования. На концептуальном уровне это «чистейшая» форма квантового машинного обучения, поэтому мы можем ожидать наиболее сильный вид квантового преимущества здесь!
Но этот рабочий процесс всё ещё ограничен на практике из-за некоторых проблем:
1. Доступ к квантовым данным: большинство реальных наборов данных (изображения, текст, табличные данные) являются классическими. Истинно квантовые данные намного сложнее получить.
2. Подготовка и контроль состояния: даже с квантовыми данными подготовка и поддержание состояния ∣ψ⟩ с высокой точностью сложна из-за шума и декогеренции.
3. Ограничения измерения: хотя мы откладываем измерение до конца, мы всё ещё сталкиваемся с ограничениями, такими как извлечение только частичной информации из квантового состояния и необходимость осторожного проектирования наблюдаемых.
В этом типе рабочего процесса цель — учиться непосредственно из квантовых систем.
2. Квантовые данные с классическими алгоритмами
До сих пор мы сосредоточились на рабочих процессах, в которых квантовые данные используются в квантовой системе. Но мы также должны рассмотреть сценарий, когда у нас есть квантовые данные и мы хотим использовать их с классическим алгоритмом ML.
На первый взгляд, это кажется естественным расширением. Если квантовые системы могут генерировать богатые многомерные данные, почему бы не использовать классические модели машинного обучения для их анализа?
На практике этот рабочий процесс возможен, но с важным ограничением.
Квантовая система описывается состоянием такого вида:
|ψ⟩=∑i=0 2 n−1 α i|i⟩
которое содержит экспоненциально много амплитуд. Однако классические алгоритмы не могут напрямую получить доступ к этому состоянию. Вместо этого мы должны измерить систему, чтобы извлечь классическую информацию, например, через ожидаемые значения:
x i=⟨ψ|O i|ψ⟩
Затем эти измеренные величины можно использовать как признаки в классической модели.
Проблема в том, что измерение принципиально ограничивает объём информации, которую мы можем извлечь. Каждое измерение предоставляет только частичную информацию о состоянии, и восстановление полного состояния потребовало бы непрактичного количества повторных экспериментов.
При этом классическое машинное обучение может сыграть ценную роль в анализе шумных данных измерений, выявлении закономерностей или улучшении обработки сигналов.
Следовательно, большинство подходов квантового машинного обучения стремятся как можно дольше хранить данные в квантовой системе, что возвращает нас к центральной проблеме этой статьи:
Как мы вообще кодируем классические данные в квантовые состояния?
Давайте поговорим о заключительном рабочем процессе.
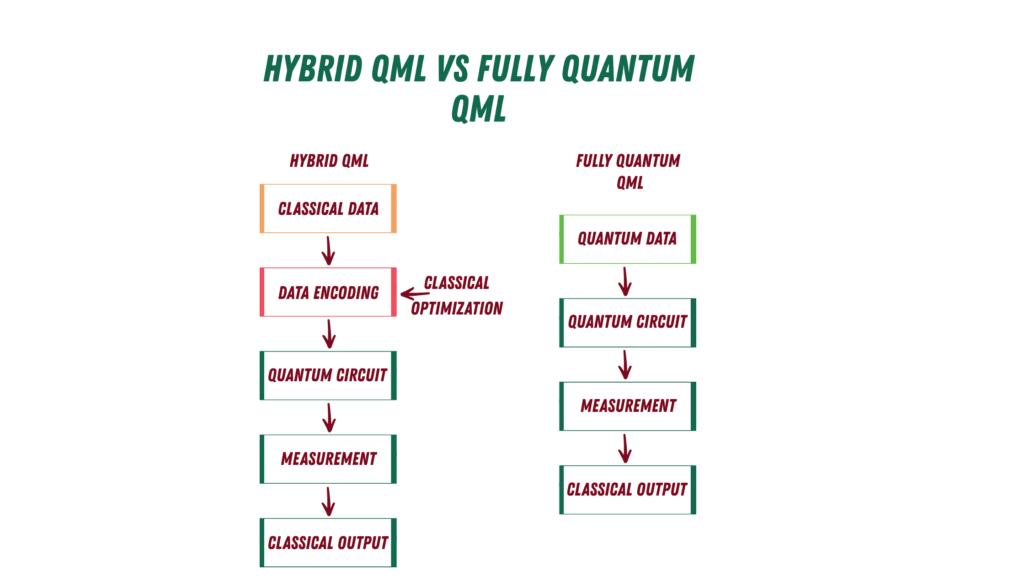
3. Классические данные с квантовой моделью (гибридное QML)
Это наиболее распространённый рабочий процесс, используемый сегодня. По сути, это модель, где мы кодируем классические данные в квантовые состояния и затем применяем QML для получения результатов. Гибридные алгоритмы QML, подобные этому, имеют 5 шагов:
1- Вход классических данных
Данные начинаются в знакомой форме:
x=(x 1,x 2,...,x n)
2- Шаг кодирования
Данные преобразуются в квантовое состояние:
x→|ψ(x)⟩
3- Квантовая обработка
Параметризованная схема обрабатывает данные:
U(θ)|ψ(x)⟩
4- Измерение
Результаты извлекаются как ожидаемые значения:
y=⟨ψ|O|ψ⟩
5- Цикл классической оптимизации
Параметры θ обновляются с использованием классических оптимизаторов.
Этот рабочий процесс создаёт новую проблему, которой нет в классическом машинном обучении:
Как эффективно кодировать классические данные в квантовую систему?
Это то, что мы ответим дальше!
Кодирование классических данных
Если мы сделаем шаг назад и сравним эти рабочие процессы, одно станет ясно: основное структурное различие — это шаг кодирования.
Поскольку большинство реальных приложений используют классические наборы данных, этот шаг обычно необходим. Итак, как мы представляем классические данные в квантовой системе?
В классических вычислениях данные хранятся в виде чисел в памяти.
В квантовых вычислениях данные должны быть представлены как квантовое состояние:
|ψ⟩=α 0|0⟩+α 1|1⟩
Для нескольких кубитов:
|ψ⟩=∑i=0 2 n−1 α i|i⟩
Где: α i — комплексные амплитуды (∑|α i|2=1). Проще говоря, кодирование означает: преобразование классических данных в амплитуды, фазы или вращения квантового состояния.
Теперь давайте внимательнее посмотрим на различные типы кодирования данных.
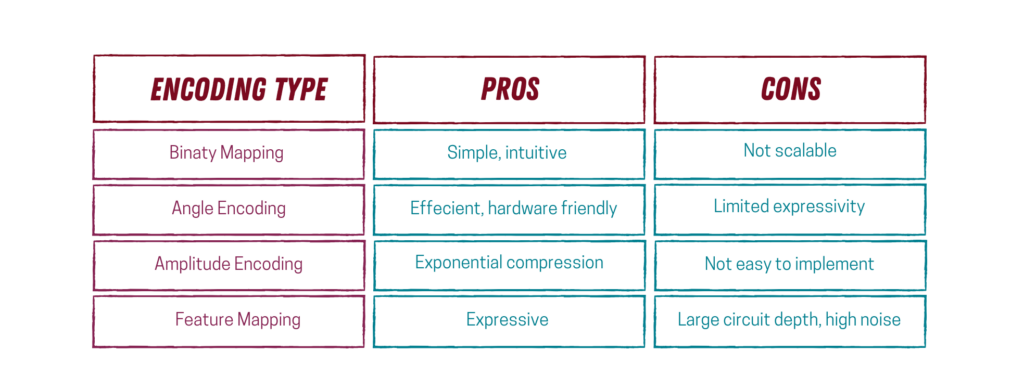
1. Базовое кодирование (двоичное отображение)
Это самый простой подход к кодированию классических данных. По сути, мы представляем классические двоичные данные непосредственно как состояния кубитов.
x=(1,0,1)→|101⟩
Пример на Qiskit
from qiskit import QuantumCircuit
qc = QuantumCircuit(3)
qc.x(0) # 1
qc.x(2) # 1
qc.draw('mpl')
Здесь каждый бит прямо отображается на кубит, и суперпозиция не используется. Этот подход работает только в том случае, если используемый набор данных простой, и он обычно используется в демонстрациях и обучении, а не в фактической реализации QML.
В этом типе кодирования данных вам понадобится один кубит на признак, что не масштабируется хорошо для более крупных и реалистичных задач.
2. Кодирование углами
Чтобы получить более богатое кодирование, вместо преобразования значений в 0 или 1, мы используем вращения для кодирования наших классических данных. Квантовые данные могут быть повёрнуты в трёх направлениях: X, Y и Z.
При кодировании углами мы берём классический признак x и отображаем его в квантовое состояние, используя вращение:
∣ψ(x)⟩=R α(x)∣0⟩, где α∈{x, y, z}.
Итак, в принципе, вы можете использовать Rx(x), Ry(x) или Rz(x).
Но не все они кодируют данные одинаково. В большинстве случаев для кодирования данных используется Rx или Ry.
R y(x)∣0⟩=c o s(2 x)∣0⟩+s i n(2 x)∣1⟩
R x(x)∣0⟩=c o s(2 x)∣0⟩−i s i n(2 x)∣1⟩
Пример на Qiskit
from qiskit import QuantumCircuit
import numpy as np
x = [0.5, 1.2]
qc = QuantumCircuit(2)
qc.ry(x[0], 0)
qc.ry(x[1], 1)
qc.draw('mpl')
Кодирование углами может, в принципе, быть реализовано с использованием вращений вокруг любой оси (например, Rx, Ry, Rz). Однако вращения вокруг оси Y и X напрямую влияют на вероятности измерения, в то время как вращения Z кодируют информацию в фазу и требуют дополнительных операций для проявления наблюдаемости.
Когда мы используем вращение для кодирования данных, непрерывные данные обрабатываются естественным образом, что приводит к компактному представлению, которое легко реализовать. В самом себе, этот метод в основном линейный, если не добавить запутанность.
3. Кодирование амплитуд
Здесь всё начинает ощущаться по-настоящему «квантовым». При кодировании амплитуд данные кодируются в амплитудах квантового состояния.
x=(x 0,x 1,x 2,x 3)
|ψ⟩=x 0|00⟩+x 1|01⟩+x 2|10⟩+x 3|11⟩
С n кубитами мы можем закодировать 2 n значений, что означает экспоненциальное сжатие.
Пример на Qiskit
from qiskit import QuantumCircuit
from qiskit.quantum_info import Statevector
import numpy as np
x = np.array([1, 1, 0, 0])
x = x / np.linalg.norm(x)
qc = QuantumCircuit(2)
qc.initialize(x, [0,1])
qc.draw('mpl')
Проблема этого подхода в том, что подготовка состояния дорога (с точки зрения схемы), что может сделать цепи глубокими и шумными. Итак, хотя кодирование амплитуд кажется мощным в теории, оно не всегда практично с текущим оборудованием.
4. Карты признаков (кодирование высокого порядка)
До сих пор мы в основном просто загружали классические данные в квантовые состояния. Карты признаков идут дальше, вводя нелинейность, захватывая взаимодействия признаков и используя запутанность.
Структура этого кодирования будет выглядеть так:
U ϕ(x)=exp(i∑j,k ϕ j k(x)Z j Z k)
Это означает, что признаки действуют не независимо; они взаимодействуют друг с другом.
Пример на Qiskit
from qiskit import QuantumCircuit
x1, x2 = 0.5, 1.0
qc = QuantumCircuit(2)
qc.ry(x1, 0)
qc.ry(x2, 1)
qc.cx(0, 1)
qc.rz(x1 * x2, 1)
qc.draw('mpl')
Этот тип кодирования является квантовым эквивалентом полиномиальных признаков или преобразований ядра. Это позволяет модели находить сложные взаимосвязи в данных.
Вы можете рассматривать карты признаков как преобразование данных в новое пространство, похожее на ядра в классическом машинном обучении. Вместо отображения данных в многомерное классическое пространство, QML отображает их в квантовое гильбертово пространство.
Заключительные мысли
Хотя квантовые компьютеры ещё не полностью готовы с аппаратной точки зрения, мы можем сделать много с их помощью сегодня. Одно из наиболее перспективных приложений квантовых компьютеров — квантовое машинное обучение. Если есть одна идея, которую стоит запомнить из этой статьи, то это:
В квантовом машинном обучении то, как вы кодируете данные, часто имеет такое же значение, как и модель, которую вы используете.
Это может показаться удивительным на первый взгляд, но это на самом деле похоже на классическое машинное обучение. Различие в том, что в QML кодирование — это не просто предварительная обработка; это часть самой модели.
И, как и более широкая область квантовых вычислений, эта область всё ещё развивается. Мы пока не знаем «лучшие» стратегии кодирования. Ограничения оборудования формируют то, что практично сегодня, и всё ещё исследуются новые подходы.
Итак, если вы хотите перейти к квантовым вычислениям, квантовое машинное обучение — одно из наиболее перспективных мест для начала. Не прыгая сразу в сложные алгоритмы, а начиная с гораздо более простого вопроса: Как мои данные могут взаимодействовать с квантовой системой?
Ответ на этот вопрос позволяет нам полностью использовать возможности квантовых компьютеров, которые у нас есть сегодня.
Ссылки и дополнительное чтение
- Schuld, M., & Petruccione, F. (2018). Supervised learning with quantum computers (Vol. 17, p. 3). Berlin: Springer.
- Havlíček, V., Córcoles, A. D., Temme, K., Harrow, A. W., Kandala, A., Chow, J. M., & Gambetta, J. M. (2019). Supervised learning with quantum-enhanced feature spaces. Nature, 567(7747), 209-212.
- Документация Qiskit: https://qiskit.org/documentation/
- Schuld, M., & Killoran, N. (2019). Quantum machine learning in feature Hilbert spaces. Physical Review Letters, 122(4), 040504.