Почему более длительное мышление может быть важнее, чем больший размер

1. Введение
На протяжении последнего десятилетия вся AI-индустрия придерживалась одного негласного принципа: интеллект может возникнуть только при масштабировании. Мы убедили себя, что для того чтобы модели по-настоящему имитировали человеческое рассуждение, нам нужны более крупные и глубокие сети. Неудивительно, что это привело к наращиванию блоков трансформеров (Vaswani et al., 2017), добавлению миллиардов параметров и обучению на дата-центрах, требующих мегаватты электроэнергии.
Но ослепляет ли эта гонка за созданием всё больших моделей нас перед гораздо более эффективным путём? Что если реальный интеллект связан не с размером модели, а с тем, сколько времени вы даёте ей рассуждать? Может ли крошечная сеть, получив свободу многократно совершенствовать собственное решение, превзойти модель, которая в тысячи раз больше?
2. Хрупкость гигантов
Чтобы понять, почему нам нужен новый подход, сначала посмотрим, почему современные модели рассуждения, такие как GPT-4, Claude и DeepSeek, всё ещё с трудом справляются со сложной логикой.
Эти модели в основном обучаются на основе целевой функции Next-Token-Prediction (NTP). Они обрабатывают подсказку через свои многомиллиардные слои параметров для прогнозирования следующего токена в последовательности. Даже когда они используют «цепь мысли» (CoT) для «рассуждения» о проблеме, они всё равно просто предсказывают слово, что, к сожалению, не является мышлением.
Такой подход имеет два недостатка.
Первый — это его хрупкость. Поскольку модель генерирует ответы токен за токеном, одна ошибка на ранних стадиях рассуждения может привести к совершенно иному, часто неправильному ответу. Модель не способна остановиться, вернуться и исправить свою внутреннюю логику перед ответом. Она должна полностью придерживаться выбранного пути, часто уверенно галлюцинируя, чтобы закончить предложение.
Вторая проблема в том, что современные модели рассуждения полагаются на запоминание, а не на логическую дедукцию. Они хорошо работают на невидимых задачах, потому что, вероятно, видели похожую проблему в своих огромных тренировочных данных. Но когда они сталкиваются с новой задачей — чем-то, что модели никогда не видели (например, бенчмарк ARC-AGI) — их массивное количество параметров становится бесполезным. Это показывает, что существующие модели могут адаптировать известное решение, вместо того чтобы сформулировать его с нуля.
3. Крошечные рекурсивные модели: обмен пространства на время
Tiny Recursion Model (TRM) (Jolicoeur-Martineau, 2025) разбивает процесс рассуждения на компактный и циклический процесс. Традиционные сети трансформеров (известные как наши LLM-модели) — это архитектуры прямого распространения, где они должны обработать входные данные в выходные за один проход. TRM же работает как рекуррентная машина небольшого одного MLP-модуля, которая может итеративно улучшать свой результат. Это позволяет ему превзойти лучшие текущие основные модели рассуждения, имея при этом менее 7 млн параметров.
Чтобы понять, как эта сеть столь эффективно решает задачи, давайте пройдём через архитектуру от входа к решению.
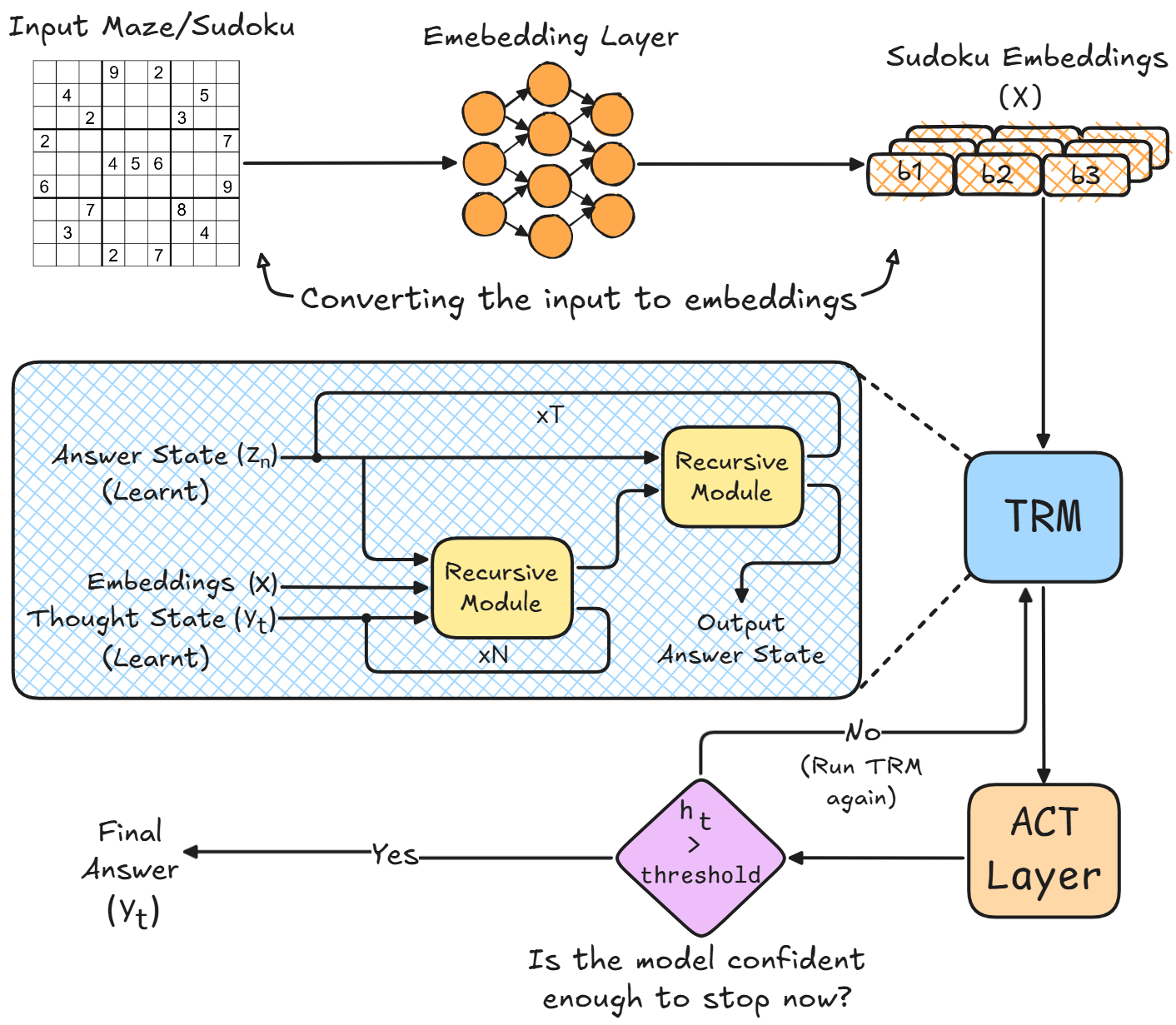
Визуальная иллюстрация всего процесса обучения/вывода TRM
3.1. Подготовка: «Тройка» состояния
В стандартных LLM единственным «состоянием» является KV-кэш истории разговора. В то время как TRM поддерживает три различных вектора информации, которые питают друг друга:
- Неизменяемый вопрос (x): Исходная задача (например, лабиринт или сетка судоку), встроенная в векторное пространство. На протяжении всего обучения/вывода это никогда не обновляется.
- Текущая гипотеза (yt): Текущее «лучшее предположение» модели об ответе. На шаге t=0 она инициализируется случайно как обучаемый параметр, который обновляется вместе с самой моделью.
- Скрытое рассуждение (zn): Этот вектор содержит абстрактные «мысли» или промежуточную логику, которую модель использует для вывода своего ответа. Подобно yt, это также инициализируется случайным параметром в начале.
3.2. Главный механизм: цикл одной сети
В сердце TRM находится одна крошечная нейронная сеть, часто состоящая всего из двух слоёв. Эта сеть не является «слоем модели» в традиционном смысле, а скорее функцией, которая вызывается повторно.
Процесс рассуждения состоит из вложенного цикла, включающего два отдельных этапа: скрытое рассуждение и уточнение ответа.
Шаг A: скрытое рассуждение (обновление zn)
Сначала модель должна только думать. Она берёт текущее состояние (три вектора, описанные выше) и запускает рекурсивный цикл для обновления собственного внутреннего понимания задачи.
Для набора подшагов (n) сеть обновляет вектор скрытой мысли zn:
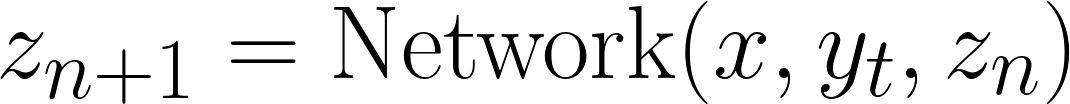
Модель рассматривает задачу (x), своё текущее лучшее предположение (yt) и свою предыдущую мысль (zn). С этим модель может выявить противоречия или логические пробелы в своём понимании, которые затем может использовать для обновления zn. Обратите внимание, что ответ yt ещё не обновляется. Модель чисто мыслит/рассуждает о задаче.
Шаг B: уточнение ответа (обновление yt)
После завершения цикла скрытого рассуждения до n шагов модель затем пытается спроецировать эти выводы на своё состояние ответа. Она использует ту же сеть для этой проекции:
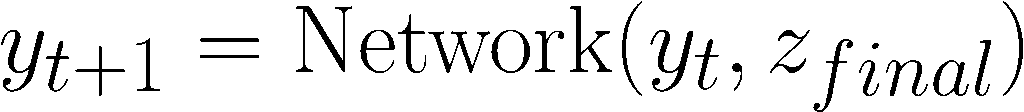
Чтобы уточнить своё состояние ответа, модель воспринимает только вектор мысли и текущее состояние ответа.
Модель преобразует свой процесс рассуждения (zn) в осязаемое предсказание (yt). Этот новый ответ затем становится входом для следующего цикла рассуждения, который в свою очередь выполняется T общих шагов.
Шаг C: цикл продолжается
После каждых n шагов уточнения мысли выполняется один шаг уточнения ответа (который в свою очередь должен быть вызван T раз). Это создаёт мощный цикл обратной связи, где модель получает возможность уточнить свой результат на протяжении нескольких итераций. Новый ответ (yt+1) может выявить новую информацию, пропущенную всеми предыдущими шагами (например, «заполнение этой ячейки судоку показывает, что 5 должна идти сюда»). Модель берёт этот новый ответ, подаёт его обратно в Шаг A и продолжает уточнять свои мысли, пока не заполнит всю сетку судоку.
3.3. Кнопка «выхода»: упрощённое адаптивное время вычисления
Ещё одна крупная инновация подхода TRM заключается в том, как он обрабатывает весь процесс рассуждения с эффективностью. Простая задача может быть решена всего за два цикла, а сложная может потребовать 50 или более, что означает, что жёсткое кодирование фиксированного количества циклов ограничительно и, следовательно, не идеально. Модель должна иметь возможность решить, решила ли она уже задачу или ей нужны дополнительные итерации для размышления.
TRM использует адаптивное время вычисления (ACT) для динамического определения момента остановки на основе сложности входной задачи.
TRM рассматривает остановку как простую задачу бинарной классификации на основе того, насколько уверена модель в своём текущем ответе.
Вероятность остановки (h):
В конце каждых T шагов уточнения ответа модель проецирует своё внутреннее состояние ответа в одно скалярное значение между 0 и 1, которое должно представлять уверенность модели:
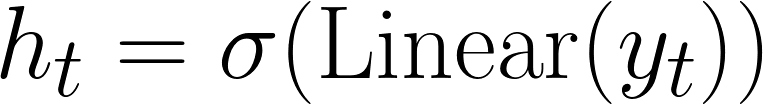
ht: вероятность остановки.
σ: сигмоидная активация для ограничения выхода между 0 и 1.
Linear: линейное преобразование, выполняемое на векторе ответа.
Целевая функция обучения:
Модель обучается с функцией потерь бинарной кросс-энтропии (BCE). Она учится выводить 1 (стоп), когда её текущий ответ yt совпадает с истинным ответом, и 0 (продолжить), если нет.
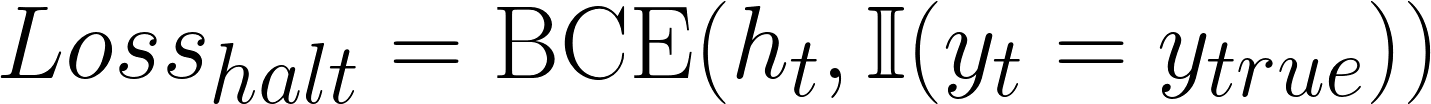
Losshalt: значение потерь, используемое для обучения модели моменту остановки.
I(•): условная функция, которая выводит 1, если утверждение внутри верно, иначе 0.
ytrue: истинное значение для того, должна ли модель остановиться или нет.
Вывод:
Когда модель работает на новой задаче, она проверяет эту вероятность ht после каждого цикла (т.е. n × T шагов).
- Если ht > порог: модель достаточно уверена. Она нажимает кнопку «выхода» и возвращает текущий ответ yt как финальный ответ.
- Если ht < порог: модель всё ещё не уверена. Она подаёт yt и zn обратно в цикл TRM для дальнейшего рассуждения.