От фрагментированных данных к действенным результатам благодаря интеллектуальному поиску. Сгенерировано ChatGPT
Есть момент, который хорошо знает каждый AI-инженер. Вы только что запустили proof of concept. Демонстрация прошла блестяще. LLM свободно отвечал на вопросы, синтезировал информацию на лету и впечатлил всех в комнате. Затем кто-то спросил у него о политике возврата компании, и он уверенно дал неправильный ответ, который не был верен уже восемь месяцев.
Этот момент — не отказ модели. Это отказ архитектуры. И это именно та проблема, которую Retrieval-Augmented Generation (RAG) была разработана для решения.
Эта статья проходит через построение production-grade RAG системы для корпоративной внутренней базы знаний, используя полностью открытый исходный код. Мы пройдем от проблемы к проектированию, через каждый этап конвейера и закончим тем, как вы действительно узнаете, работает ли система. Цель состоит не в том, чтобы охватить все возможные вариации, а чтобы дать вам четкую ментальную модель и практическую основу, на которой вы можете строить.
Что мы рассмотрим
- Почему LLM недостаточно для корпоративного поиска в базе знаний
- Архитектура RAG: как два конвейера работают вместе
- Построение индексирующего конвейера: загрузка, разбиение, встраивание и хранение
- Построение конвейера поиска и генерации: поиск, переранжирование и формирование запроса
- Оценка: измерение качества на каждом этапе, а не только в конце
- Где заканчивается RAG и начинается тонкая настройка
Проблема, которую стоит решать
Большинство средних и крупных организаций располагают тысячами внутренних документов: инженерных руководств, политик HR, руководств по соответствию, инструкций по адаптации, спецификаций продукта. Они разбросаны по Confluence, SharePoint, Notion, общим дискам и потокам писем, которые никто не трогал три года.
Средний сотрудник тратит две-три часа в неделю просто на поиск информации, которая уже существует где-то. Старшие инженеры становятся случайными агентами поддержки. Новые сотрудники месяцами становятся независимо производительными не потому, что им не хватает способностей, а потому что институциональные знания разбросаны и недоступны для поиска.
Наивный ответ — указать LLM все это и задать вопросы. Проблема в том, что LLM статичны. Один раз обученные, они не знают о вашем последнем выпуске продукта, политике, которая изменилась в прошлом квартале, или постмортеме, которое ваша команда опубликовала вчера. Тонкая настройка помогает со стилем и тоном, но она дорогая, медленно обновляется и не показывает, откуда произошел ответ. В регулируемой индустрии этот пробел в аудитируемости неприемлем.
RAG находит золотую середину. Во время запроса система извлекает наиболее релевантные документы из вашей базы знаний и дает их LLM в качестве контекста. Модель генерирует ответ, основанный на этих документах, а не на том, что она выучила во время обучения. Каждый ответ можно проследить до источника. База знаний может быть обновлена за минуты. И ничего не должно покидать вашу инфраструктуру.
Архитектура
Прежде чем переходить к отдельным компонентам, полезно увидеть форму всей системы. RAG — это не одна модель, это два конвейера, работающих вместе.
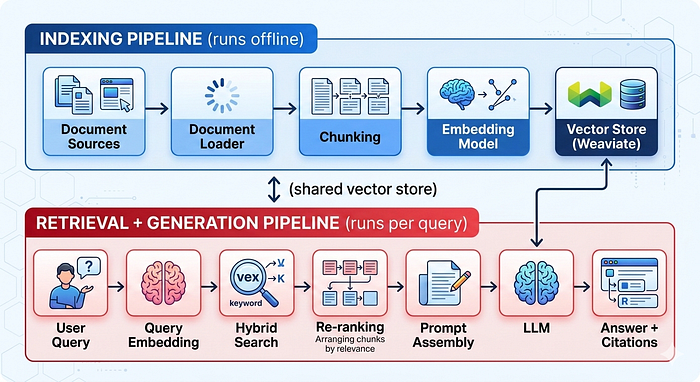
Индексирующий конвейер запускается один раз при первой настройке системы, а затем поэтапно всякий раз, когда добавляются или изменяются документы. Его задача — взять необработанные документы, разбить их на значимые части, преобразовать эти части в векторные представления и сохранить их.
Конвейер поиска и генерации запускается при каждом запросе пользователя. Он берет вопрос, находит наиболее релевантные части, собирает их в запрос и просит LLM сгенерировать ответ, основанный на этом контексте.
Два конвейера используют хранилище векторов как точку встречи. Это единственное решение по проектированию, разделяющее индексирование и поиск, делает всю систему обновляемой без переподготовки.
Фаза первая: индексирующий конвейер
Загрузка ваших документов
Первая сложность — просто получить ваши документы в пригодную для использования форму. Корпоративные знания редко находятся в одном месте или в одном формате.
Для этого мы используем LlamaIndex. Где LangChain предлагает загрузчики документов, LlamaIndex идет дальше: он поставляется со сто с лишним нативными коннекторами для систем, таких как Confluence, Notion, SharePoint, Google Drive и S3, и отслеживает хеши документов, так что при последующих запусках переиндексируются только измененные файлы. Для базы знаний, которая постоянно эволюционирует, это поэтапное синхронизирование — не просто хорошо иметь, это необходимо.
from llama_index.readers.confluence import ConfluenceReader
from llama_index.core import SimpleDirectoryReader
# Извлечение из Confluence
confluence_docs = ConfluenceReader(
base_url="https://yourcompany.atlassian.net/wiki",
oauth2={"client_id": "...", "token": "..."}
).load_data(space_key="ENGG", page_status="current")
# Извлечение из локального каталога (PDFs, Markdown, DOCX)
local_docs = SimpleDirectoryReader(
input_dir="./knowledge_base",
required_exts=[".pdf", ".docx", ".md"],
recursive=True
).load_data()Что проверить здесь: Логируйте сколько документов успешно загружено, сколько пропущено и загружены ли какие-либо ошибки молча. Отказ загрузчика на этом этапе создает пробел в знаниях, который позже проявится как неправильный или недостающий ответ, и его будет очень сложно проследить.
Разбиение на части: этап, в котором большинство команд ошибаются
Если вы возьмете из этой статьи только одно, пусть это будет: качество вашего разбиения на части больше влияет на производительность вашей системы, чем выбор LLM или даже вашей модели встраивания.
Причина ясна. Когда пользователь задает вопрос, система извлекает части, а не полные документы. Если часть обрывается посередине аргумента, или разбивает таблицу на два сегмента, или настолько велика, что разбавляет сигнал, система поиска не может выполнить свою работу должным образом.
Простое разбиение фиксированного размера: разрезание каждых 512 токенов без учета границ предложений или абзацев быстро реализуется и последовательно посредственно. Для корпоративного контента мы используем SentenceWindowNodeParser LlamaIndex, который индексирует на уровне предложения для точного поиска, но расширяется до окружающего окна предложений при генерации ответа. Вы получаете хирургический поиск без потери контекста, который делает ответ логичным.
from llama_index.core.node_parser import SentenceWindowNodeParser
parser = SentenceWindowNodeParser.from_defaults(
window_size=3, # 3 предложения с каждой стороны во время генерации
window_metadata_key="window",
original_text_metadata_key="original_text"
)
nodes = parser.get_nodes_from_documents(all_docs)Для более длинных документов, таких как файлы политик или технические руководства, лучше работает иерархический подход: индексирование на уровне абзаца, но возврат полного раздела при генерации. Правильная стратегия разбиения зависит от типа вашего контента; нет универсального ответа.
Что проверить здесь: Вручную просмотрите около пятидесяти случайных частей. Спросите себя, может ли каждая из них стоять отдельно как значимый ответ на какой-то вопрос. Если более одной из пяти кажется фрагментом предложения или сиротским пунктом, ваш размер части слишком мал или перекрытие недостаточно.
Преобразование текста в векторы
Каждую часть нужно преобразовать в числовой вектор, чтобы мы могли измерить сходство между запросом и документом. Это работа модели встраивания, и выбор важнее, чем многие инженеры понимают.
Мы используем BAAI/bge-large-en-v1.5, открытую модель от Пекинской академии искусственного интеллекта, которая входит в число лучших открытых моделей по бенчмарку MTEB. Она полностью запускается локально, что для большинства предприятий — не опция, а обязательное требование. Отправка внутренних документов на внешний API встраивания — это проблема местоположения данных, которая остановит production rollout.
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-large-en-v1.5",
query_instruction="Represent this sentence for searching relevant passages: "
)Префикс инструкции в последней строке специфичен для моделей BGE и стоит того, чтобы его сохранить. Это асимметричная оптимизация поиска, которая измеримо улучшает точность. Одно правило, которое нужно рассматривать как абсолютное: одна и та же модель встраивания должна использоваться как для индексирования, так и для запросов. Эти две операции производят векторы, которые живут в одном и том же математическом пространстве. Смешивание моделей, даже обновление до более новой версии посередине развертывания, нарушает это пространство и делает ваш индекс неработающим.