Несмотря на беспрецедентный выпуск высокоразрешающих климатических данных в глобальном масштабе, превращение их в локальные и действенные выводы остаётся сложной задачей. Часто проблема заключается не в отсутствии данных, а в сложности формата данных.
Климатические данные обычно сохраняются в формате NetCDF (Network Common Data Form). Эти файлы:
- Содержат огромные многомерные массивы (тензоры обычно имеют форму время × широта × долгота × переменные)
- Требуют пространственной маскировки, временной агрегации и выравнивания систем координат ещё до статистического анализа
- От природы не подходят для табличных структур (например, базы данных SQL или Pandas DataFrame), которые типично используют городские планировщики и экономисты
Такой разрыв в структуре создаёт пробел в переводе: физические сырые данные есть, но социально-экономические выводы, которые должны быть из них получены, отсутствуют.
Базовые источники данных
Один из аспектов надёжного конвейера заключается в том, что он может интегрировать традиционные базовые показатели с прогнозами на будущее:
- ERA5 Переанализ: Предоставляет исторические климатические данные (1991-2020) такие как температура и влажность
- CMIP6 Прогнозы: Предлагает потенциальные будущие климатические сценарии на основе различных путей выбросов
С помощью этих источников данных можно выполнять локализованное обнаружение аномалий вместо опоры исключительно на глобальные средние значения.
Локальные базовые уровни: определение экстремальной жары
Критическая проблема в климатическом анализе заключается в решении о том, как определить "экстремальные" условия. Фиксированный глобальный порог (например, 35°C) недостаточен, так как локальная адаптация сильно варьируется от региона к региону.
Поэтому мы характеризуем экстремальную жару порогом на основе процентилей, полученным из исторических данных:
import numpy as np
import xarray as xr
def compute_local_threshold(tmax_series: xr.DataArray, percentile: int = 95) -> float:
return np.percentile(tmax_series, percentile)
T_threshold = compute_local_threshold(Tmax_historical_baseline)Такой подход гарантирует, что экстремальные события определяются относительно локальных климатических условий, делая анализ более контекстным и значимым.
Термодинамическая инженерия признаков: температура влажного термометра
Сама по себе температура недостаточна для точного определения человеческого теплового стресса. Влажность, которая влияет на механизм охлаждения организма через испарение, также является основным фактором. Температура влажного термометра (WBT), которая представляет собой комбинацию температуры и влажности, является хорошим показателем физиологического стресса. Вот формула, которую мы используем на основе приближения Стулла (2011), простая и быстрая для вычисления:
import numpy as np
def compute_wet_bulb_temperature(T: float, RH: float) -> float:
wbt = (
T * np.arctan(0.151977 * np.sqrt(RH + 8.313659))
+ np.arctan(T + RH)
- np.arctan(RH - 1.676331)
+ 0.00391838 * RH**1.5 * np.arctan(0.023101 * RH)
- 4.686035
)
return wbtУстойчивые температуры влажного термометра выше 31–35°C приближаются к пределам выживаемости человека, что делает это критическим признаком в моделировании рисков.
Перевод климатических данных в воздействие на человека
Чтобы выйти за пределы физических переменных, мы переводим климатическое воздействие в воздействие на человека, используя упрощённую эпидемиологическую модель.
def estimate_heat_mortality(population, base_death_rate, exposure_days, AF):
return population * base_death_rate * exposure_days * AFВ этом случае смертность моделируется как функция численности населения, базового уровня смертности, продолжительности воздействия и приписываемой доли, представляющей риск.
Хотя упрощённая, эта формулировка позволяет переводить температурные аномалии в интерпретируемые показатели воздействия, такие как предполагаемая избыточная смертность.
Моделирование экономического воздействия
Изменение климата также влияет на экономическую производительность. Эмпирические исследования предполагают нелинейную связь между температурой и экономическим выпуском, с снижением производительности при более высоких температурах.
Мы приближаем это с помощью простой полиномиальной функции:
def compute_economic_loss(temp_anomaly):
return 0.0127 * (temp_anomaly - 13)**2Хотя упрощённая, эта функция отражает ключевой вывод о том, что экономические потери ускоряются по мере того, как температуры отклоняются от оптимальных условий.
Тематическое исследование: контрастирующие климатические контексты
Чтобы проиллюстрировать конвейер, мы рассматриваем два контрастирующих города:
- Джакобабад (Пакистан): город с экстремальной базовой жарой
- Якутск (Россия): город с холодным климатом базово
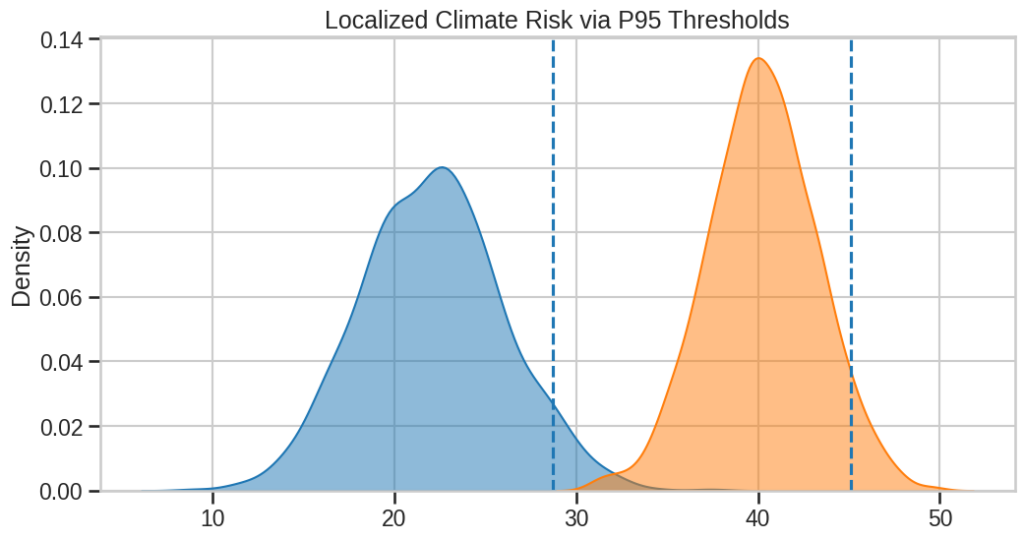
Локализованные пороги P95, показывающие, как экстремальная жара определяется относительно региональных распределений температур, а не фиксированных глобальных пределов
| Город | Население | Базовые смерти/год | Риск жары (%) | Предполагаемые смерти от жары/год |
| Джакобабад | 1,17 млн | ~8200 | 0,5% | ~41 |
| Якутск | 0,36 млн | ~4700 | 0,1% | ~5 |
Несмотря на использование одного и того же конвейера, результаты значительно отличаются из-за локальных климатических базовых линий. Это подчёркивает важность моделирования, учитывающего контекст.
Архитектура конвейера: от данных к выводам
Полный конвейер следует структурированному рабочему процессу:
import xarray as xr
import numpy as np
ds = xr.open_dataset("cmip6_climate_data.nc")
tmax = ds["tasmax"].sel(lat=28.27, lon=68.43, method="nearest")
threshold = np.percentile(tmax.sel(time=slice("1991", "2020")), 95)
future_tmax = tmax.sel(time=slice("2030", "2050"))
heat_days_mask = future_tmax > threshold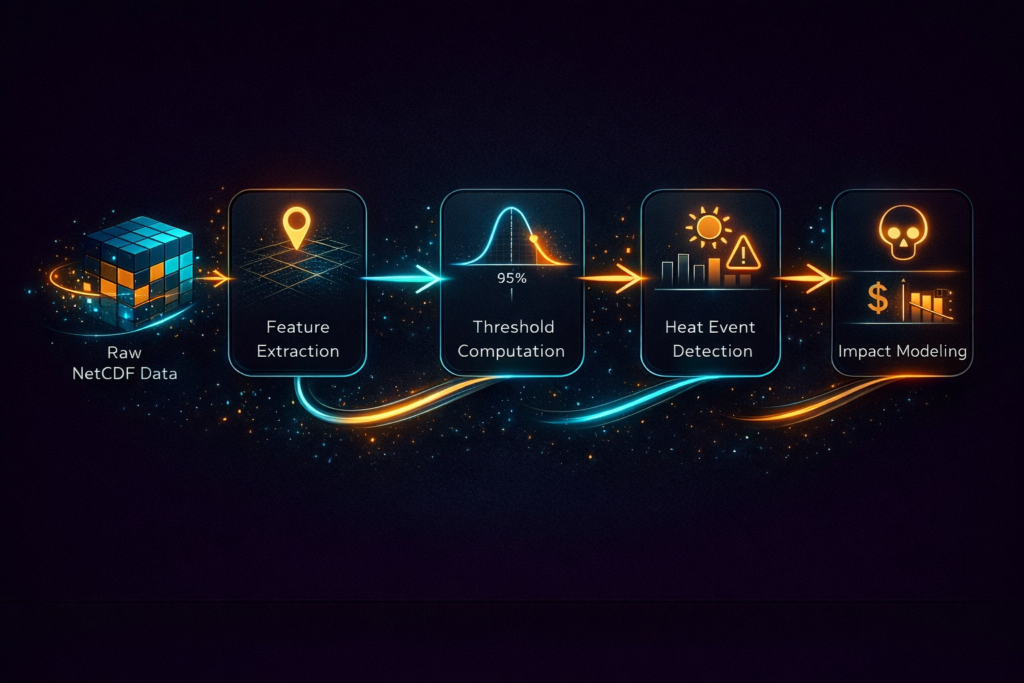
Сквозной рабочий процесс от загрузки сырого NetCDF к моделированию воздействия
Этот метод можно разделить на серию этапов, которые отражают традиционный рабочий процесс обработки данных. Он начинается с загрузки данных, которая предполагает загрузку сырых файлов NetCDF в вычислительную среду. Затем выполняется извлечение пространственных признаков, при котором выделяются релевантные переменные, такие как максимальная температура, для определённой географической координаты. Следующий этап — вычисление базовой линии с использованием исторических данных для определения порога на основе процентилей, который указывает на экстремальные ситуации.
Как только базовая линия установлена, обнаружение аномалий выявляет будущие временные интервалы, когда температуры превышают порог, по сути идентифицируя события жары. Наконец, эти выявленные явления передаются в модели воздействия, которые преобразуют их в понятные результаты, такие как подсчёт смертельных случаев и экономический ущерб.
При надлежащей оптимизации эта последовательность операций позволяет эффективно обрабатывать большие наборы климатических данных, превращая сложные многомерные данные в структурированные и интерпретируемые выводы.
Ограничения и предположения
Как и любой аналитический конвейер, этот также зависит от набора упрощающих предположений, которые следует учитывать при интерпретации результатов. Оценки смертности основываются на предположении единообразной уязвимости населения, что едва ли отражает изменения в разных группах.
%%END%%