Как гибридный конвейер PyMuPDF + GPT-4 Vision заменил £8000 ручного инженерного труда, и почему последние модели не были ответом
Кто-то зашел в мой кабинет и спросил, смогу ли я помочь извлечь номера редакций из более чем 4700 PDF-файлов инженерных чертежей. Они переходили на новую систему управления активами и нуждались в текущем значении REV для каждого чертежа — небольшом поле, спрятанном в блоке названий каждого документа. Альтернативой было то, что команда инженеров открывала каждый PDF по очереди, искала блок названий и вручную вводила значение в электронную таблицу. При двух минутах на один чертеж это примерно 160 человеко-часов. Четыре недели времени одного инженера. При полной ставке примерно £50 в час это более £8000 на выполнение задачи, которая не имеет инженерной ценности, кроме заполнения столбца в электронной таблице.
Это была не задача AI. Это была задача проектирования систем с реальными ограничениями: бюджет, требования к точности, смешанные форматы файлов и команда, которой нужны результаты, которым они могут доверять. AI был одним компонентом решения. Инженерные решения вокруг него — вот что действительно заставило систему работать.
Скрытая сложность «простых» PDF-файлов
Инженерные чертежи — это не обычные PDF-файлы. Некоторые были созданы в CAD-программах и экспортированы как текстовые PDF-файлы, где вы можете программно извлекать текст. Другие, особенно устаревшие чертежи 1990-х и 2000-х годов, были отсканированы с бумажных оригиналов и сохранены как PDF-файлы на основе изображений. Вся страница — это плоское растровое изображение без текстового слоя вообще.
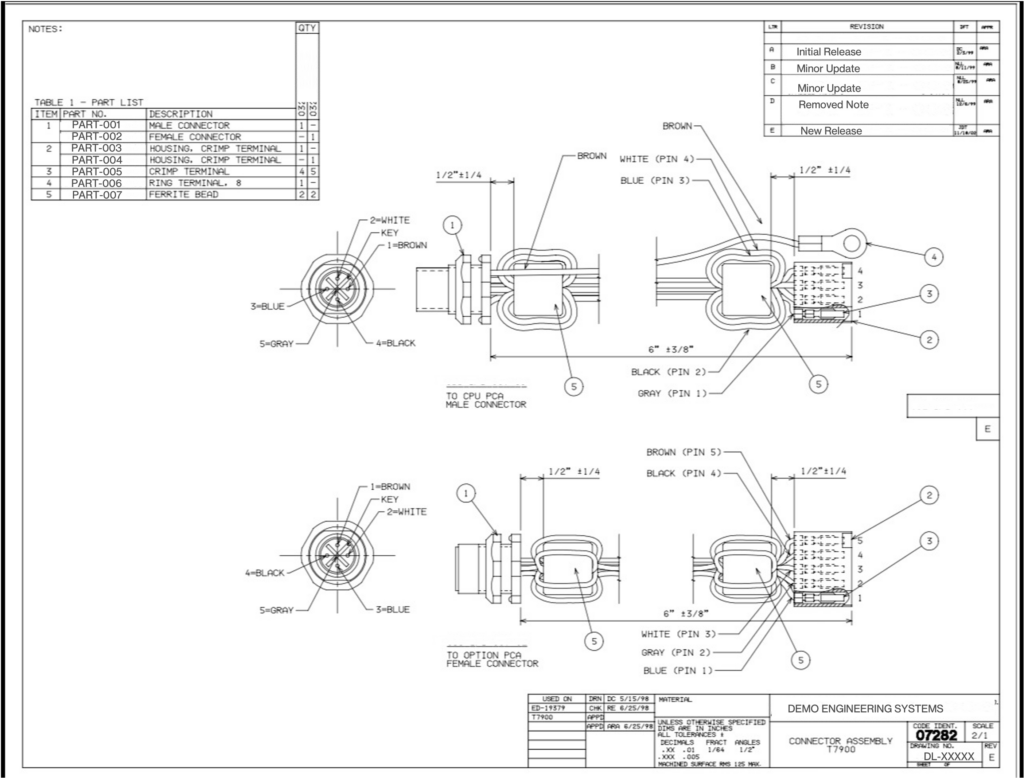
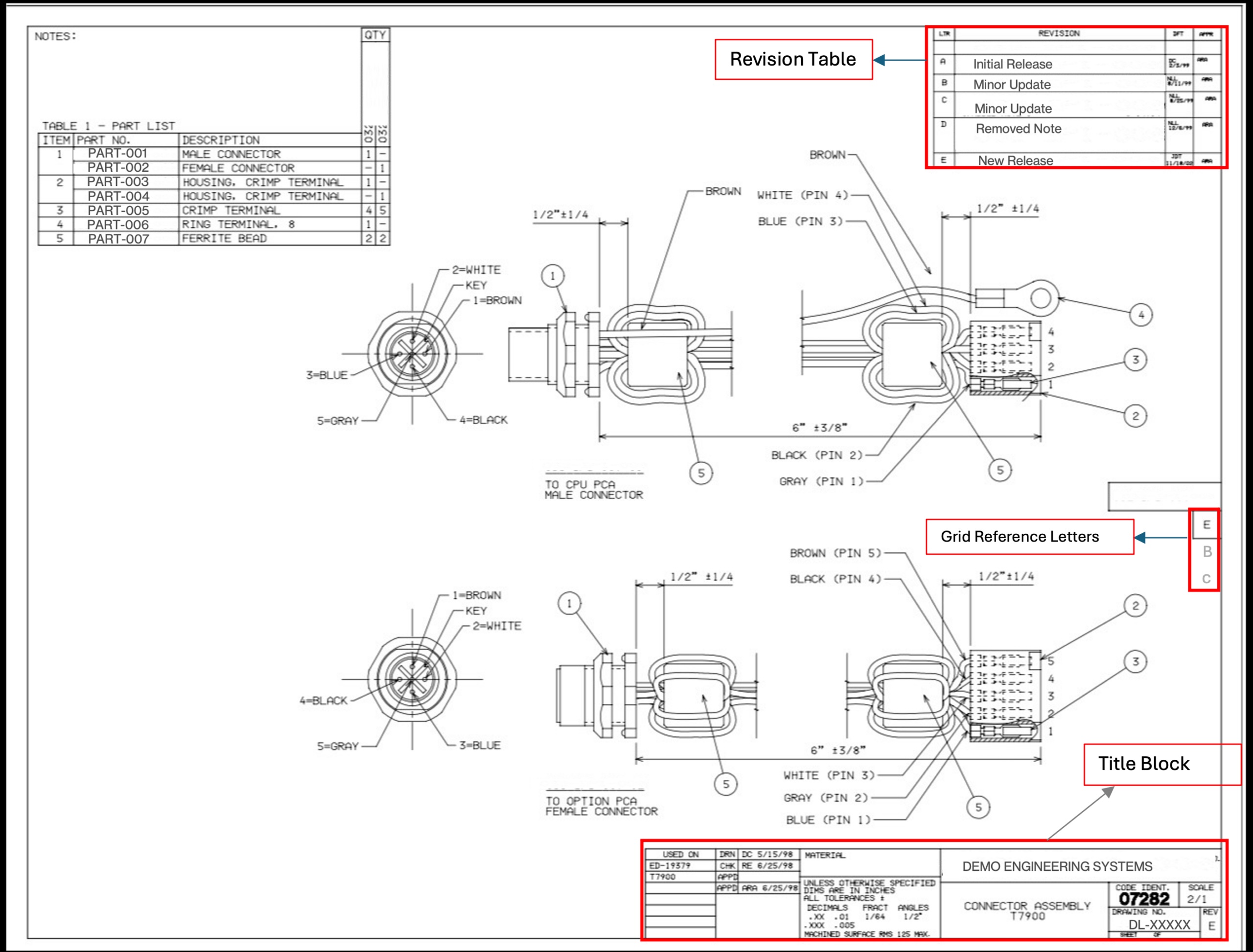
Наш корпус состоял примерно на 70-80% из текстовых файлов и на 20-30% из файлов на основе изображений. Но даже текстовое подмножество было коварным. Значения REV появлялись минимум в четырех форматах: гибридные числовые версии, такие как 1-0, 2-0 или 5-1; отдельные буквы, такие как A, B, C; двойные буквы, такие как AA или AB; и иногда пустые или отсутствующие поля. Некоторые чертежи были повернуты на 90 или 270 градусов. Многие имели таблицы истории редакций (многострочные журналы изменений), расположенные прямо рядом с текущим полем REV, что является очевидной ловушкой для ложных срабатываний. Буквы сетки по краю чертежа могли легко приниматься за редакции с одной буквой.
Почему полностью AI-подход был неправильным выбором
Вы могли бросить каждый документ в GPT-4 Vision и считать это завершением, но при примерно $0,01 за изображение и 10 секундах на вызов это будет $47 и почти 100 минут времени API. Более важно, что вы платили бы за дорогостоящий вывод на документах, где несколько строк Python могли бы извлечь ответ в миллисекундах.
Логика была простой: если документ имеет извлекаемый текст и значение REV следует предсказуемым шаблонам, нет причины задействовать LLM. Сохраните модель для случаев, когда детерминированные методы не срабатывают.
Гибридная архитектура, которая сработала
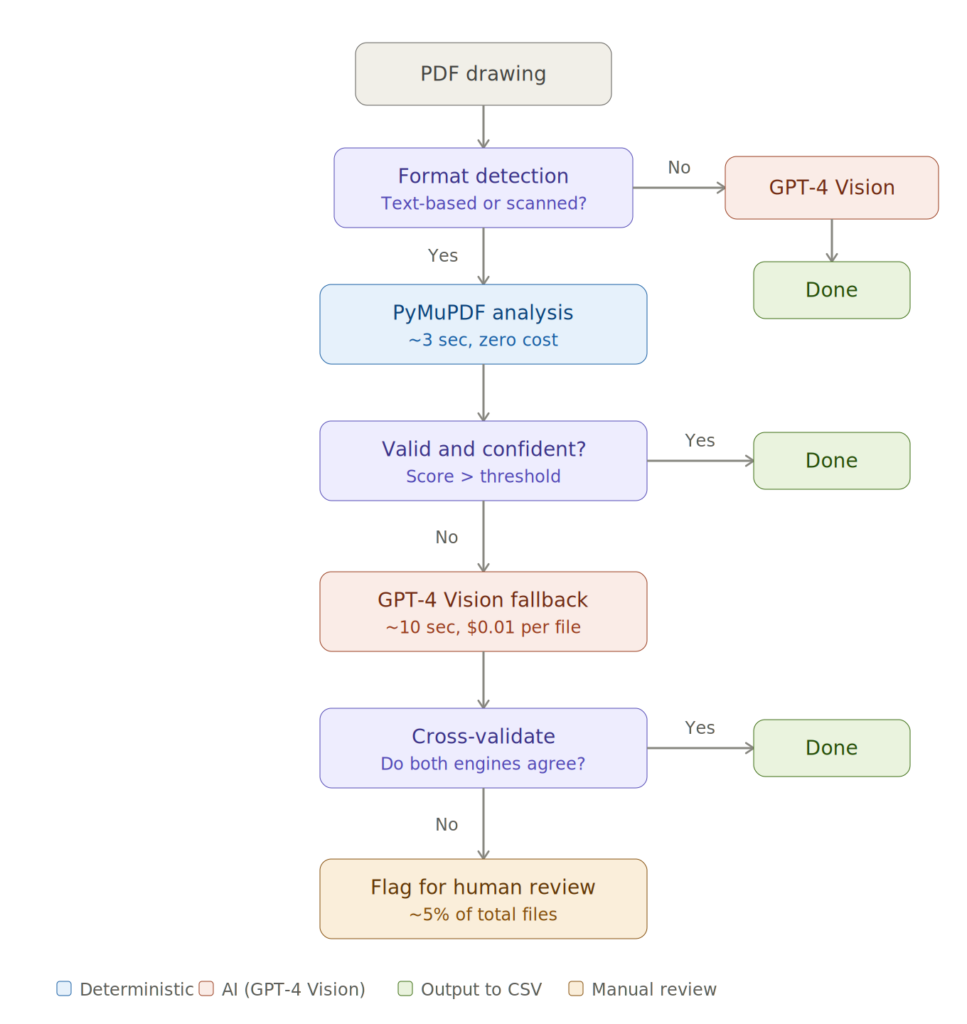
Этап 1: извлечение PyMuPDF (детерминированное, нулевая стоимость). Для каждого PDF мы пытаемся выполнить извлечение на основе правил, используя PyMuPDF. Логика сосредоточена на нижнем правом квадранте страницы, где находятся блоки названий, и ищет текст рядом с известными якорями, такими как «REV», «DWG NO», «SHEET» и «SCALE». Функция оценки ранжирует кандидатов по близости к этим якорям и соответствию известным форматам REV.
def extract_native_pymupdf(pdf_path: Path) -> Optional[RevResult]:
"""Try native PyMuPDF text extraction with spatial filtering."""
try:
best = process_pdf_native(
pdf_path,
brx=DEFAULT_BR_X, # bottom-right X threshold
bry=DEFAULT_BR_Y, # bottom-right Y threshold
blocklist=DEFAULT_REV_2L_BLOCKLIST,
edge_margin=DEFAULT_EDGE_MARGIN
)
if best and best.value:
value = _normalize_output_value(best.value)
return RevResult(
file=pdf_path.name,
value=value,
engine=f"pymupdf_{best.engine}",
confidence="high" if best.score > 100 else "medium",
notes=best.context_snippet
)
return None
except Exception:
return NoneСписок блокировки отфильтровывает распространенные ложные срабатывания: маркеры разделов, ссылки на сетку, указатели страниц. Ограничение поиска областью блока названий снизило ложные совпадения до минимума.
Этап 2: GPT-4 Vision (для всего, что не обработал этап 1). Когда извлечение на основе платформы возвращает пусто, либо потому что PDF основан на изображениях, либо макет текста слишком неоднозначен, мы преобразуем первую страницу в PNG и отправляем ее в GPT-4 Vision через Azure OpenAI.
def pdf_to_base64_image(self, pdf_path: Path, page_idx: int = 0,
dpi: int = 150) -> Tuple[str, int, bool]:
"""Convert PDF page to base64 PNG with smart rotation handling."""
rotation, should_correct = detect_and_validate_rotation(pdf_path)
with fitz.open(pdf_path) as doc:
page = doc[page_idx]
pix = page.get_pixmap(matrix=fitz.Matrix(dpi/72, dpi/72), alpha=False)
if rotation != 0 and should_correct:
img_bytes = correct_rotation(pix, rotation)
return base64.b64encode(img_bytes).decode(), rotation, True
else:
return base64.b64encode(pix.tobytes("png")).decode(), rotation, FalseМы выбрали 150 DPI после тестирования. Более высокие разрешения увеличивали размер полезной нагрузки и замедляли вызовы API, не улучшая точность. Более низкие разрешения теряли детали при сканировании предельного качества.
Что сломалось в боевых условиях
Два класса проблем возникли только при работе с полным корпусом из 4700 документов.
Неоднозначность ротации. Инженерные чертежи часто хранятся в альбомной ориентации, но кодирование ориентации в метаданных PDF варьируется дико. Некоторые файлы правильно устанавливают /Rotate. Другие физически поворачивают содержимое, но оставляют метаданные на нуле. Мы решили это с помощью эвристики: если PyMuPDF может извлечь более десяти текстовых блоков со странице без коррекции, ориентация, вероятно, верна независимо от того, что говорят метаданные. В противном случае мы применяем коррекцию перед отправкой в GPT-4 Vision.
Галлюцинация модели. Модель иногда цеплялась за значения из примеров в самом запросе вместо чтения реального чертежа. Если каждый пример показывал REV «2-0», модель развивала смещение к выводу «2-0» даже когда чертеж явно показывал «A» или «3-0». Мы исправили это двумя способами: мы разнообразили примеры по всем допустимым форматам с явными предупреждениями против запоминания, и мы добавили четкие инструкции, различающие таблицу истории редакций (многострочный журнал изменений) от текущего поля REV (единственное значение в блоке названий).
КРИТИЧЕСКИЕ ПРАВИЛА - ИЗБЕГАЙТЕ ЭТОГО:
✗ НЕ извлекайте из ТАБЛИЦ ИСТОРИИ РЕДАКЦИЙ
(столбцы: REV | ОПИСАНИЕ | ДАТА)
- Мы хотим текущий REV из блока названий (единственное значение)
✗ НЕ извлекайте буквы сетки (A, B, C вдоль краев)
✗ НЕ извлекайте маркеры разделов ("РАЗДЕЛ C-C", "РАЗДЕЛ B-B")Результаты и компромиссы
Мы проверили по выборке из 400 файлов с вручную проверенной истинностью.
| Метрика | Гибридный (PyMuPDF + GPT-4) | Только GPT-4 |
|---|---|---|
| Точность (n=400) | 96% | 98% |
| Время обработки (n=4,730) | ~45 минут | ~100 минут |
| Стоимость API | ~$10-15 | ~$47 (все файлы) |
| Частота человеческой проверки | ~5% | ~1% |
Разрыв в точности 2% был ценой за снижение времени выполнения на 55 минут и ограниченные затраты. Для миграции данных, где инженеры в любом случае проверяют процент значений, 96% с частотой флагирования 5% для проверки было приемлемо. Если бы используемый вариант требовал соответствия нормативам, мы бы запустили GPT-4 на каждом файле.
Позже мы провели тестирование более новых моделей, включая GPT-5+, по той же выборке валидации из 400 файлов. Точность была сравнима с GPT-4.1 на уровне 98%. Новые модели не предоставили значимый прирост для этой задачи извлечения по более высокой стоимости за вызов и более медленному выводу. Мы выбрали GPT-4.1. Когда задача — это пространственно ограниченное сопоставление шаблонов в w