Воспроизводимый бенчмарк, демонстрирующий 33-кратное снижение задержки объяснений благодаря встраиванию символического мышления непосредственно в архитектуру модели
Emmimal P Alexander
30 марта 2026
16 минут чтения
TL;DR
- KernelExplainer SHAP требует ~30 мс на предсказание (даже с небольшим справочным набором)
- Нейро-символическая модель генерирует объяснения внутри прямого прохода за 0,9 мс
- Это 33-кратное ускорение с детерминированными результатами
- Полнота обнаружения мошенничества идентична (0,8469), только небольшое снижение AUC
- Без отдельного объяснителя, без случайности, без дополнительных задержек
- Весь код работает на датасете Kaggle Credit Card Fraud Detection
Полный код: https://github.com/Emmimal/neuro-symbolic-xai-fraud/
Момент, когда проблема стала реальной
Я отлаживал систему обнаружения мошенничества поздно вечером и захотел понять, почему модель отметила конкретную транзакцию. Я вызвал KernelExplainer, передал справочный набор данных и стал ждать. Через три секунды у меня была диаграмма с распределением влияния признаков. Я запустил её снова, чтобы проверить значение, и получил немного другие цифры.
Тогда я понял, что в способе генерации объяснений была структурная ограничение. Модель была детерминирована. Объяснение — нет. Я объяснял согласованное решение с непостоянным методом, и ни задержка, ни случайность не были приемлемы, если это когда-нибудь должно было работать в реальном времени.
Эта статья о том, что я построил взамен, что это стоило с точки зрения производительности и что получилось правильно, включая один результат, который меня удивил.
Если объяснения не могут быть созданы мгновенно и согласованно, они не могут использоваться в системах мошенничества, работающих в реальном времени.
Ключевой вывод: Объяснимость не должна быть этапом постобработки. Она должна быть частью архитектуры модели.
Ограничения SHAP в условиях реального времени
Чтобы быть точнее относительно того, что именно делает SHAP: фреймворк SHAP от Lundberg и Lee вычисляет значения Шепли (концепция из теории кооперативных игр), которые приписывают выход модели её входным признакам. KernelExplainer, вариант модели-агностик, аппроксимирует эти значения, используя взвешенную линейную регрессию над выборкой коалиций признаков. Справочный набор данных служит базовой линией, а nsamples контролирует, сколько коалиций оценивается на предсказание.
Эта аппроксимация чрезвычайно полезна для отладки модели, выбора признаков и анализа постфактум.
Изучаемое здесь ограничение уже и более критично: когда объяснения должны быть сгенерированы во время вывода, присоединены к отдельным предсказаниям, под ограничениями задержки реального времени.
Когда вы подключаете SHAP к реальному конвейеру обнаружения мошенничества, вы запускаете алгоритм аппроксимации, который:
- Зависит от справочного набора данных, который нужно поддерживать и передавать во время вывода
- Производит результаты, которые меняются в зависимости от
nsamplesи состояния случайности - Требует 30 мс на выборку при сокращённой конфигурации
Диаграмма ниже показывает, как выглядит такой постфактум результат — глобальный рейтинг признаков, вычисленный после того, как предсказание уже было сделано.
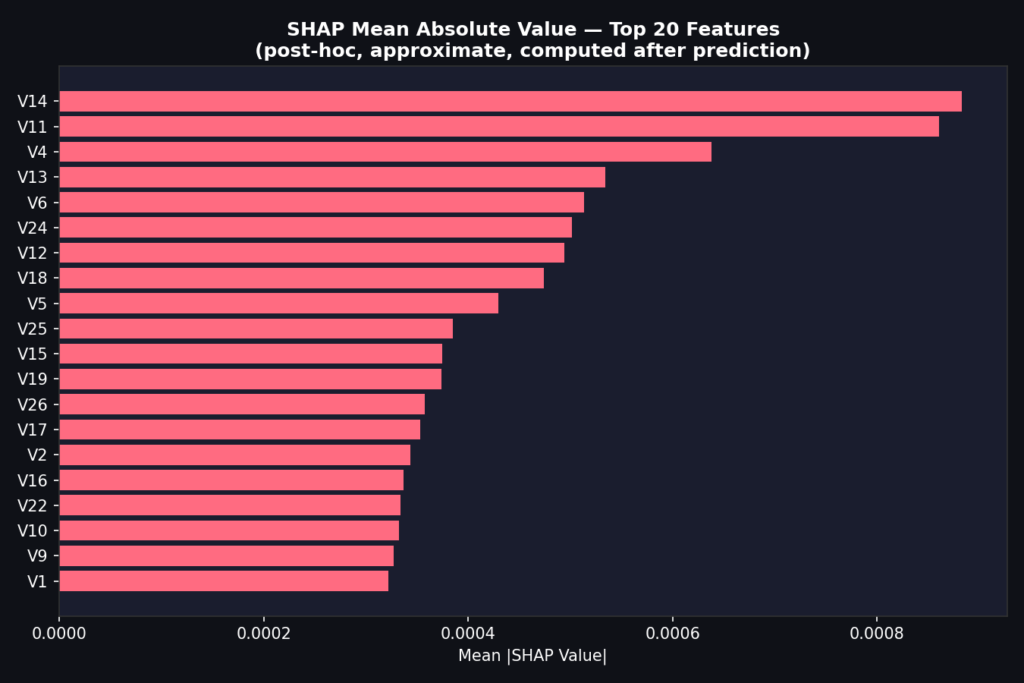
Среднее значение важности признаков SHAP по 100 тестовым выборкам, вычисленное с использованием KernelExplainer. V14 занимает первое место, что согласуется с опубликованным EDA по этому датасету. Это полезно для глобального понимания модели — но вычисляется после предсказания, не может быть присоединено к одному решению в реальном времени и будет давать немного другие значения при следующем запуске из-за выборки Монте-Карло. Изображение автора.
В бенчмарке, который я провел на датасете Kaggle creditcard, сам SHAP напечатал предупреждение:
Using 200 background data samples could cause slower run times.
Consider using shap.sample(data, K) or shap.kmeans(data, K)
to summarize the background as K samples.Это подчёркивает компромисс между размером справочного набора и вычислительной стоимостью в SHAP. 30 мс при 200 справочных выборках — это нижний предел. Более крупные справочные наборы, которые улучшают стабильность атрибуции, повышают стоимость.
Построенная мною нейро-символическая модель требует 0,898 мс для предсказания и объяснения вместе. Нет нижнего предела, о котором нужно беспокоиться, потому что нет отдельного объяснителя.
Датасет
Все эксперименты используют датасет Kaggle Credit Card Fraud Detection, охватывающий 284 807 реальных транзакций по кредитным картам от европейских держателей карт в сентябре 2013 года, из которых 492 подтверждены как мошенничество.
Размер : (284807, 31)
Доля мошенничества : 0,1727%
Образцы мошенничества : 492
Легальные образцы : 284 315Признаки V1 через V28 — это PCA-преобразованные главные компоненты. Исходные признаки анонимизированы и не раскрываются в датасете. Amount — это стоимость транзакции. Time был исключён.
Amount был масштабирован с помощью StandardScaler. Я применил SMOTE исключительно к тренировочному набору для устранения дисбаланса класса. Тестовый набор был сохранён с реальным распределением мошенничества 0,17% на протяжении всего эксперимента.
Размер тренировочного набора после SMOTE : 454 902
Доля мошенничества после SMOTE : 50,00%
Тестовый набор : 56 962 образца | 98 подтверждённых мошенничествСтруктура тестового набора важна: 98 случаев мошенничества из 56 962 образцов — это реальные условия работы этой задачи. Любая модель, которая хорошо работает здесь, справляется с действительно сложной задачей.
Две модели, одно сравнение
Базовая модель: стандартная нейронная сеть
Базовая модель — это четырёхслойный MLP с пакетной нормализацией и dropout, стандартная архитектура для выявления мошенничества в табличных данных.
class FraudNN(nn.Module):
def __init__(self, input_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 128), nn.BatchNorm1d(128),
nn.ReLU(), nn.Dropout(0.3),
nn.Linear(128, 64), nn.BatchNorm1d(64),
nn.ReLU(), nn.Dropout(0.3),
nn.Linear(64, 32), nn.ReLU(),
nn.Linear(32, 1), nn.Sigmoid(),
)Она делает предсказание и ничего больше. Объяснение этого предсказания требует отдельного вызова SHAP.
Нейро-символическая модель: объяснение как архитектура
Нейро-символическая модель имеет три компонента, работающих вместе: нейронный остов, слой символических правил и слой слияния, который объединяет оба сигнала.
Нейронный остов изучает скрытые представления из всех 29 признаков. Слой символических правил запускает шесть дифференцируемых правил параллельно, каждое из которых вычисляет мягкую активацию между нулём и единицей, используя сигмоид. Слой слияния берёт оба выхода и производит итоговую вероятность.
class NeuroSymbolicFraudDetector(nn.Module):
"""
Вход
|--- Нейронный остов (скрытые представления мошенничества)
|--- Слой символических правил (6 дифференцируемых правил)
|
Слой слияния --> P(мошенничество) + активации_правил
"""
def __init__(self, input_dim, feature_names):
super().__init__()
self.backbone = nn.Sequential(
nn.Linear(input_dim, 64), nn.BatchNorm1d(64),
nn.ReLU(), nn.Dropout(0.2),
nn.Linear(64, 32), nn.BatchNorm1d(32), nn.ReLU(),
)
self.symbolic = SymbolicRuleLayer(feature_names)
self.fusion = nn.Sequential(
nn.Linear(32 + 1, 16), nn.ReLU(), # 32 от остова + 1 от слоя символических правил (взвешенный итог активации правил)
nn.Linear(16, 1), nn.Sigmoid(),
)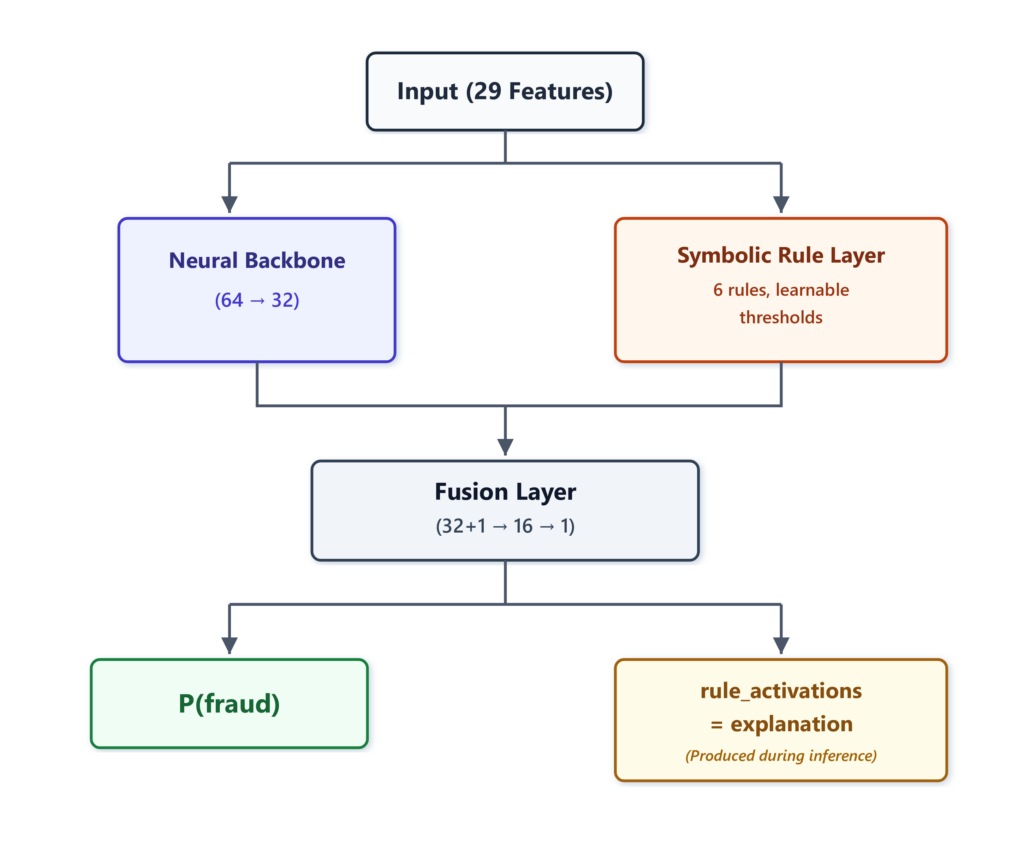
Нейро-символическая модель запускает два пути параллельно при каждом прямом проходе. Нейронный остов производит скрытые представления мошенничества. Слой символических правил оценивает шесть дифференцируемых правил против обучаемых пороговых значений. Слой слияния объединяет оба сигнала в единую вероятность мошенничества. Активации правил — объяснение — являются естественным выходом этого вычисления, а не отдельным шагом. Изображение автора.