Экономичный способ получить оценку неопределённости на уровне токенов для нейронного машинного перевода
Нейронный машинный перевод значительно эволюционировал с момента появления Google Translate в 2007 году. Однако системы НМП по-прежнему «галлюцинируют», как и любые другие модели — особенно при работе с низкоресурсными областями или при переводе между редкими языковыми парами.
Когда Google Translate предоставляет результат, вы видите только выходной текст, а не распределения вероятностей или метрики неопределённости для каждого слова или предложения. Даже если вам не нужна эта информация, знание о том, где модель уверена, а где нет, может быть действительно ценным для внутренних целей. Например, простые части можно передать быстрой и дешёвой модели, а для сложных можно выделить больше ресурсов.
Но как мы можем оценить и, самое главное, «откалибровать» эту неопределённость? Первое, что приходит в голову — это оценить распределение выходных вероятностей для каждого токена, например, путём расчёта его энтропии. Это вычислительно просто, универсально для всех архитектур модели и, как показано ниже, фактически коррелирует со случаями, когда модель НМП неуверена.
Однако ограничения этого подхода очевидны:
- Во-первых, модель может выбирать между несколькими синонимами и с точки зрения выбора токена быть неуверенной.
- Во-вторых, и это более важно, это просто метод «чёрного ящика», который ничего не объясняет о природе неопределённости. Возможно, модель действительно не видела ничего подобного во время обучения. Или, возможно, она просто галлюцинировала несуществующее слово или грамматическую конструкцию.
Существующие подходы решают эту проблему достаточно хорошо, но все имеют свои нюансы:
- Семантическая энтропия группирует выходы модели по семантическому смыслу, но требует генерации 5–10 выходов для одного входа, что вычислительно дорого (и, честно говоря, когда я пытался воспроизвести это на моём помеченном наборе данных, наблюдаемая семантическая сходство слов в этих кластерах было сомнительным).
- Метрики вроде xCOMET достигают SOTA-уровня оценки качества на уровне токена, но требуют тонкой настройки 3,5 миллиардов параметров модели XLM-R на дорогостоящих данных с аннотациями качества и, помимо этого, функционируют как чёрный ящик.
- Интроспекция модели через анализ заметности выглядит интересно, но также имеет проблемы с интерпретацией.
Предложенный ниже метод может сделать вычисление неопределённости эффективным. Поскольку большинство установок НМП уже имеют две модели — прямую модель (язык1 → язык2) и обратную модель (язык2 → язык1) — мы можем использовать их для вычисления интерпретируемых сигналов неопределённости.
После создания перевода с помощью прямой модели мы можем «поместить» инвертированную пару перевод-источник в обратную модель, используя принуждение учителя (как если бы она её создала сама), а затем извлечь транспонированную карту кросс-внимания и сравнить её с соответствующей картой из прямой модели. Результаты ниже показывают, что этот подход позволяет получить интерпретируемые сигналы на уровне токена в большинстве случаев.
Кроме того, нет необходимости переобучать тяжёлую модель НМП. Достаточно обучить лёгкий классификатор на признаках из сравнения матриц, сохраняя веса основной модели замороженными.
Как выглядит правильно и неправильно
Начнём с простого примера перевода с французского на английский, где всё ясно только из визуализации.
"Elle aime manger des pommes → She likes to eat apples"
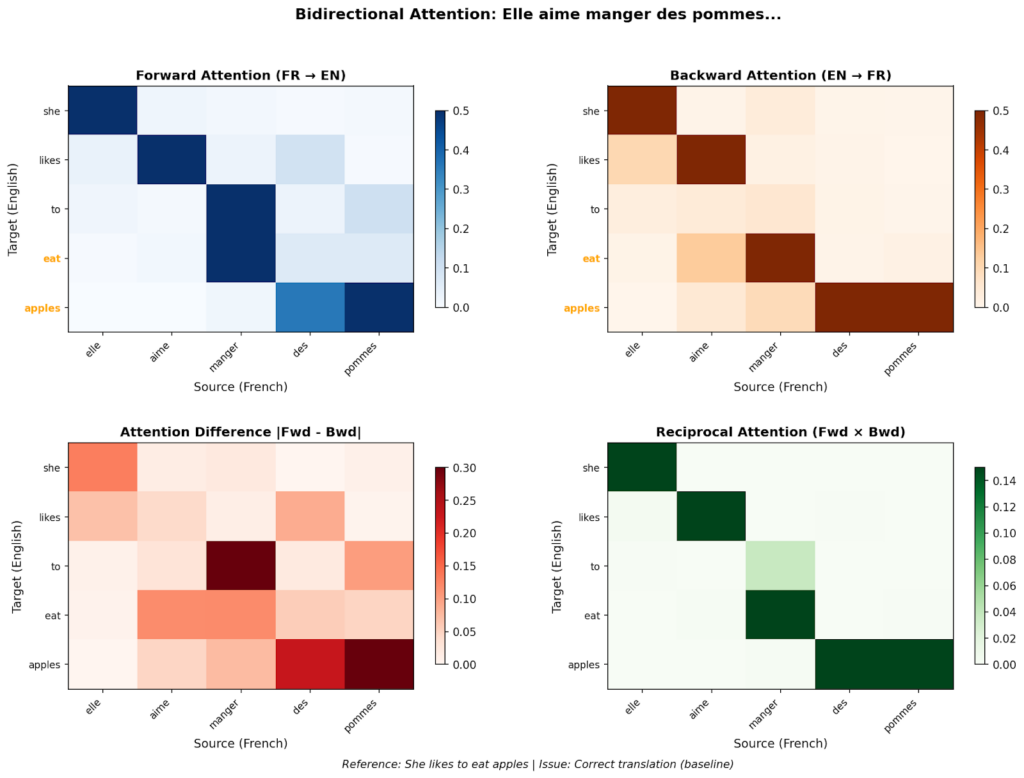
Рисунок 1. Пример корректного перевода модели. Для обоих прямого и обратного перевода паттерн кросс-внимания очевиден: каждый токен переведённого предложения имеет связь с токенами исходного предложения ("She"↔"Elle", "likes"↔"aime", "apples"↔"pommes"), за исключением частиц и артиклей — даже эти имеют "якорь" к соответствующему глаголу или существительному. Изображение автора
Теперь давайте сравним это с неправильным переводом НМП:
"La femme dont je t'ai parlé travaille à cette université" (правильный перевод: "The woman I told you about works at this university")
Что произвела модель:
"The woman whose wife I told you about that university"
Откуда взялось это дополнительное слово "wife"?
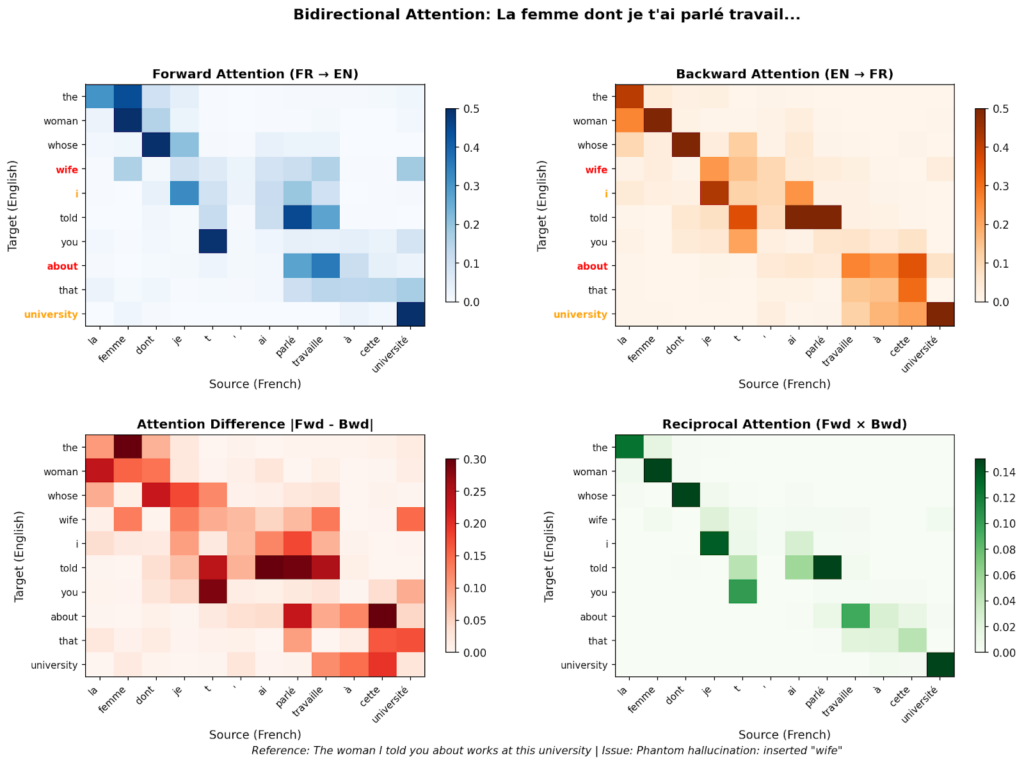
Рисунок 2: Паттерн 1-к-1 для токенов, увиденный в первом примере, здесь разрушается. Как отмечено, это само по себе недостаточное условие для утверждения, что модель галлюцинирует. Однако это ясный сигнал того, что обратный переводчик не может «найти» обратный путь перевода. Это особенно очевидно в карте Взаимного внимания, где как дополнительное слово "wife", так и семантически связанные токены во второй части предложения имеют размытые оценки. Изображение автора
Двунаправленная взаимная проверка
Вычисление двунаправленного внимания. Обратите внимание, что обратная модель использует принуждение учителя. Она получает предварительно созданный английский перевод и проверяет, соответствует ли он исходному французскому источнику, при этом новое французское предложение не генерируется. Это проверка выравнивания, а не круговой перевод.
def get_bidirectional_attention(dual_model, src_tensor, tgt_tensor):
"""Extract forward/backward cross-attention and reciprocal map."""
dual_model.eval()
with torch.no_grad():
fwd_attn, bwd_attn = dual_model.get_cross_attention(src_tensor, tgt_tensor)
# Align to full target/source lengths for element-wise comparison
B, T = tgt_tensor.shape
S = src_tensor.shape[1]
fwd_aligned = torch.zeros(B, T, S, device=src_tensor.device)
bwd_aligned = torch.zeros(B, T, S, device=src_tensor.device)
if T > 1:
fwd_aligned[:, 1:T, :] = fwd_attn
if S > 1:
bwd_aligned[:, :, 1:S] = bwd_attn.transpose(1, 2)
reciprocal = fwd_aligned * bwd_aligned
return fwd_aligned, bwd_aligned, reciprocalВесь воспроизводимый код доступен через репозиторий GitHub проекта.
В начале работы по этой теме я пробовал использовать прямой круговой перевод. Однако из-за слабой производительности моделей, обученных на одном GPU, а также из-за неоднозначности перевода было трудно сравнивать источник и результат кругового перевода на уровне токена, так как предложения могли полностью потерять своё значение. Более того, сравнение матриц внимания обратной и прямой моделей для трёх разных предложений — источника, перевода и воспроизведённого источника из кругового перевода — было бы затратным.
Когда паттерны менее очевидны: китайский → английский
Для языковых пар со сходной структурой (например, французский↔английский) паттерн «1-к-1 для токена» интуитивен. Но что насчёт типологически отдалённых языков?
Китайский → английский включает:
- Гибкий порядок слов. Китайский, как и английский, является SVO, но допускает топикализацию и опущение местоимения.
- Отсутствие пробелов между словами. Токенизаторы должны сегментировать перед разделением на подслова.
- Логографическая система письма. Символы соответствуют морфемам, а не фонемам.
Карты внимания становятся труднее интерпретировать, просто глядя на картинку, однако выученные признаки всё ещё способны захватить качество выравнивания.
Давайте посмотрим на этот пример ошибки семантической инверсии:
这家公司的产品质量越来越差客户都很不满意(правильный перевод: This company's product quality is gettingworse, customers are verydissatisfied)
Выходные данные модели:
The quality of products of the company is increasinglysatisfiedwith the customer.
Слово «不满意» означает «недовольный», но то, что произвела модель — это ровно противоположное. Не говоря уже о том, что весь результат перевода — это бессмыслица.
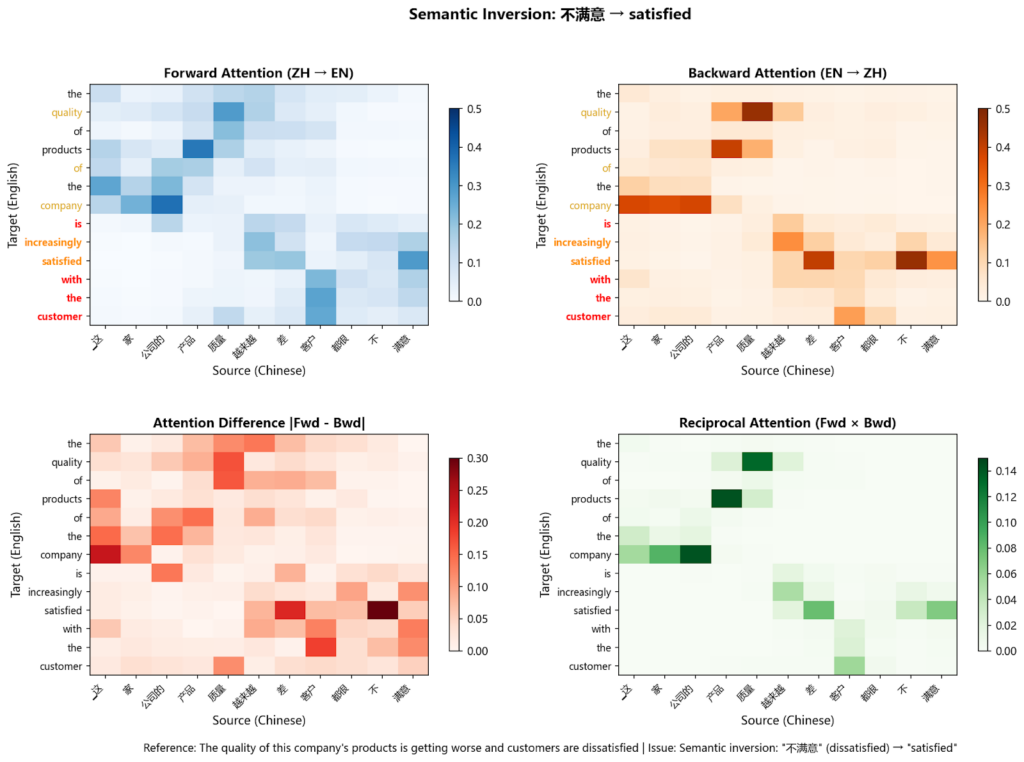
Рисунок 3: Несмотря на то, что людям намного сложнее интерпретировать паттерн здесь, в отличие от примера французский → английский, слабые оценки Взаимного внимания во второй части предложения всё ещё выделяются, указывая на то, где модель совершает семантические ошибки. Изображение автора
Несмотря на то, что паттерн значительно менее заметен визуально, обучаемый классификатор контроля качества всё ещё может его захватить. Именно поэтому мы извлекаем 75 признаков, основанных на выравнивании внимания различных видов, что объясняется более подробно ниже.
Экспериментальная установка
Ядро НМП намеренно недообучено для этой установки. Почти совершенный переводчик производит мало ошибок для обнаружения. Тем не менее, для построения системы оценки качества нам нужны переводы, которые иногда (или даже часто) терпят неудачу.