Практическое руководство по измерению взаимосвязей между переменными для отбора признаков в кредитном скоринге.
Спасибо за ваш отзыв и интерес к моей предыдущей статье. Поскольку несколько читателей спросили, как воспроизвести анализ, я решил поделиться полным кодом на GitHub как для этой статьи, так и для предыдущей. Это позволит вам легко воспроизвести результаты, лучше понять методологию и более детально изучить проект.
В этой публикации мы показываем, что анализ взаимосвязей между переменными в кредитном скоринге служит двум основным целям:
- Оценка способности объясняющих переменных различать дефолт (см. раздел 1.1)
- Снижение размерности путем изучения взаимосвязей между объясняющими переменными (см. раздел 1.2)
- В разделе 1.3 мы применяем эти методы к набору данных, представленному в нашей предыдущей статье.
- В заключении мы подводим итоги и выделяем основные моменты, которые могут быть полезны на собеседованиях, будь то стажировка или постоянная должность.
По мере совершенствования наших навыков моделирования мы часто оглядываемся назад и улыбаемся нашим ранним попыткам, первым моделям, которые мы строили, и ошибкам, которые мы совершили на этом пути.
Я помню, как строил модель скоринга, используя ресурсы Kaggle, не понимая по-настоящему, как анализировать взаимосвязи между переменными. Независимо от того, включали ли они две непрерывные переменные, одну непрерывную и одну категориальную переменную или две категориальные переменные, мне не хватало как графической интуиции, так и статистических инструментов, необходимых для надлежащего их изучения.
Только на третьем году, во время проекта кредитного скоринга, я полностью осознал их важность. Именно этот опыт побуждает меня настоятельно рекомендовать всем, кто строит свою первую модель скоринга, серьезно отнестись к анализу взаимосвязей между переменными.
Почему важно изучать взаимосвязи между переменными
Первая цель — выявить переменные, которые лучше всего объясняют изучаемое явление, например, прогнозирование дефолта.
Однако корреляция не означает причинность. Любой вывод должен поддерживаться:
- академическими исследованиями
- экспертизой в данной области
- визуализацией данных
- и экспертным суждением
Вторая цель — снижение размерности. Определив надлежащие пороги, мы можем предварительно выбрать переменные, которые показывают значимые связи с целевой переменной или с другими предикторами. Это помогает снизить избыточность и повысить производительность модели.
Это также дает предварительное руководство о том, какие переменные, вероятно, будут сохранены в финальной модели, и помогает выявить потенциальные проблемы моделирования. Например, если переменная без значимой связи с целевой переменной в итоге окажется в финальной модели, это может указывать на слабость в процессе моделирования. В таких случаях важно вернуться к предыдущим этапам и выявить возможные недостатки.
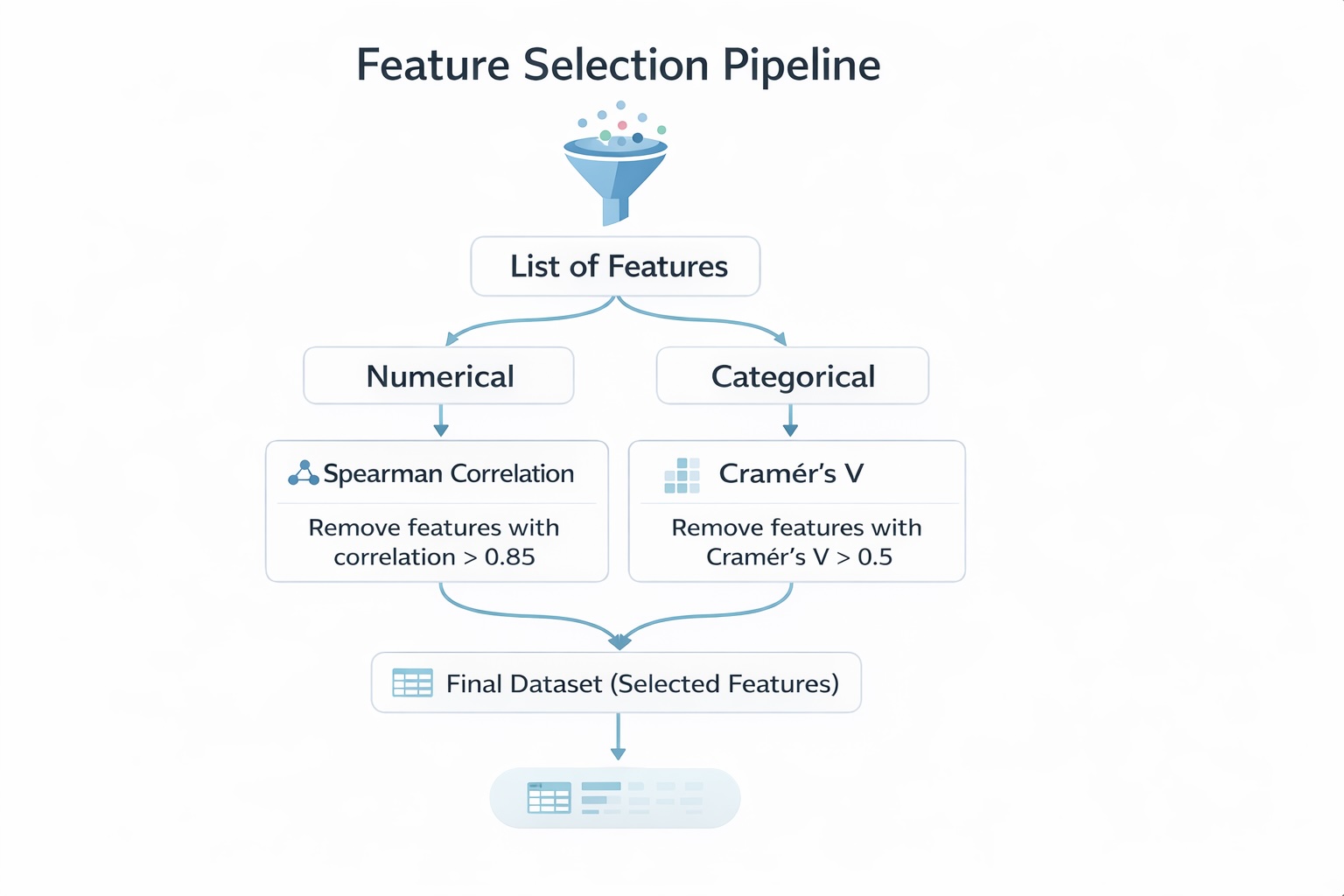
В этой статье мы сосредотачиваемся на трех типах взаимосвязей:
- Две непрерывные переменные
- Одна непрерывная и одна качественная переменная
- Две качественные переменные
Все анализы проводятся на тренировочном наборе данных. В предыдущей статье мы рассмотрели выбросы и пропущенные значения, что является необходимым условием перед любым статистическим анализом. Поэтому мы будем работать с очищенным набором данных для анализа взаимосвязей между переменными.
Выбросы и пропущенные значения могут существенно искажать как статистические показатели, так и визуальные интерпретации взаимосвязей. Вот почему критически важно обеспечить, чтобы этапы предварительной обработки, такие как обработка пропущенных значений и выбросов, выполнялись тщательно и надлежащим образом.
Цель этой статьи не в том, чтобы дать исчерпывающий список статистических тестов для измерения ассоциаций между переменными. Вместо этого цель состоит в том, чтобы дать вам необходимые основы для понимания важности этого этапа при построении надежной модели скоринга.
Представленные здесь методы относятся к наиболее часто используемым на практике. Однако в зависимости от контекста аналитики могут использовать дополнительные или более продвинутые методы.
К концу этой статьи вы должны быть в состоянии уверенно ответить на следующие три вопроса, которые часто задают на стажировках или собеседованиях при приеме на работу:
- Как вы измеряете взаимосвязь между двумя непрерывными переменными?
- Как вы измеряете взаимосвязь между двумя качественными переменными?
- Как вы измеряете взаимосвязь между качественной переменной и непрерывной переменной?
Графический анализ
Изначально я хотел пропустить этот этап и перейти прямо к статистическому тестированию. Однако, поскольку эта статья предназначена для начинающих в моделировании, это, пожалуй, самая важная часть.
Когда у вас есть возможность визуализировать данные, вы должны ею воспользоваться. Визуализация может раскрыть много информации о структуре данных, часто больше, чем один статистический показатель.
Этот этап особенно важен на этапе исследования, а также при принятии решений и обсуждении с экспертами в предметной области. Выводы, полученные из визуализаций, всегда должны быть проверены:
- специалистами предметной области
- контекстом исследования
- и соответствующей академической или научной литературой
Объединив эти точки зрения, мы можем исключить переменные, которые не имеют отношения к проблеме или которые могут привести к ошибочным выводам. В то же время мы можем выявить наиболее информативные переменные, которые действительно помогают объяснить изучаемое явление.
Когда этот этап выполняется тщательно и подкреплен академическими исследованиями и экспертной валидацией, мы можем быть более уверены в последующих статистических тестах, которые в итоге сводят информацию к показателям, таким как p-значения или коэффициенты корреляции.
1. Применение в кредитном скоринге
В кредитном скоринге цель состоит в том, чтобы выбрать из набора потенциальных переменных те, которые лучше всего объясняют целевую переменную, как правило, дефолт.
Вот почему мы изучаем взаимосвязи между переменными.
Мы увидим позже, что некоторые модели чувствительны к мультиколлинеарности, которая возникает, когда несколько переменных содержат подобную информацию. Поэтому снижение избыточности является необходимым.
В нашем случае целевая переменная является бинарной (дефолт против недефолта), и мы стремимся различать ее, используя объясняющие переменные, которые могут быть либо непрерывными, либо категориальными.
Графически мы можем оценить дискриминирующую способность этих переменных, то есть их способность прогнозировать результат дефолта. В следующем разделе мы представляем графические методы и статистические тесты, которые могут быть автоматизированы для анализа связи между непрерывными или категориальными объясняющими переменными и целевой переменной, используя языки программирования, такие как Python.
1.1 Оценка прогнозирующей способности
В этом разделе мы представляем графические и статистические инструменты, используемые для оценки способности как непрерывных, так и категориальных объясняющих переменных захватить связь с целевой переменной, а именно дефолт.
1.1.1 Непрерывная переменная в сравнении с бинарной целевой переменной
Если переменная, которую мы оцениваем, непрерывна, цель состоит в том, чтобы сравнить ее распределение в двух классах целевой переменной:
- недефолт (def = 0)
- дефолт (def = 1)
Мы можем использовать:
- диаграммы размаха для сравнения медиан и дисперсии
- графики плотности (KDE) для сравнения распределений
- эмпирические функции распределения (ECDF)
Основная идея проста:
Отличается ли распределение переменной между дефолтерами и недефолтерами?
Если ответ да, переменная может иметь дискриминирующую способность.
Предположим, мы хотим оценить, насколько хорошо person_income различает между заемщиками, допустившими дефолт, и теми, кто не допустил. Графически мы можем сравнить сводную статистику, такую как среднее или медиана, а также распределение через графики плотности или кумулятивные функции распределения (CDF) для дефолтеров и недефолтеров. Результирующая визуализация показана ниже.
def plot_continuous_vs_categorical(
df,
continuous_var,
categorical_var,
category_labels=None,
figsize=(12, 10),
sample=None
):
"""
Сравнение непрерывной переменной по категориям
с использованием boxplot, KDE и ECDF (макет 2x2).
"""
sns.set_style("white")
data = df[[continuous_var, categorical_var]].dropna().copy()
# Дополнительная выборка
if sample:
data = data.sample(sample, random_state=42)
categories = sorted(data[categorical_var].unique())
# Сопоставление меток (необязательно)
if category_labels:
labels = [category_labels.get(cat, str(cat)) for cat in categories]
else:
labels = [str(cat) for cat in categories]
fig, axes = plt.subplots(2, 2, figsize=figsize)
# --- 1. Диаграмма размаха ---
sns.boxplot(
data=data,
x=categorical_var,
y=continuous_var,
ax=axe