У вас есть модель. У вас есть один GPU. Обучение займёт 72 часа. Вы заказываете вторую машину с четырьмя дополнительными GPU — и теперь вам нужно, чтобы ваш код их использовал. Именно в этот момент большинство практиков сталкиваются с препятствием. Не потому что распределённое обучение концептуально сложно, а потому что инженерия, необходимая для его правильной реализации — группы процессов, логирование с учётом ранга, инициализация семени сэмплера, барьеры контрольных точек — разбросана по десяткам руководств, каждое из которых охватывает только один кусок головоломки.
Эта статья — руководство, которое я хотел бы иметь, когда впервые масштабировал обучение за пределы одного узла. Мы создадим полный, production-grade конвейер многоузлового обучения с нуля, используя DistributedDataParallel (DDP) PyTorch. Каждый файл модульный, каждое значение настраивается, и каждая концепция распределённых вычислений сделана явной. К концу вы получите кодовую базу, которую можно поместить в любой кластер и сразу начать обучение.
Что мы рассмотрим: мысленную модель DDP, чистую модульную структуру проекта, управление распределённым жизненным циклом, эффективную загрузку данных на ранги, цикл обучения со смешанной точностью и накоплением градиентов, логирование и сохранение контрольных точек с учётом ранга, скрипты запуска многоузловой системы и ловушки производительности, которые сбивают с толку даже опытных инженеров.
Полная кодовая база доступна на GitHub. Каждый блок кода в этой статье взят непосредственно из этого репозитория.
2. Как работает DDP — мысленная модель
Прежде чем писать какой-либо код, нам нужна ясная мысленная модель. DistributedDataParallel (DDP) — это не магия, это хорошо определённый паттерн коммуникации, построенный на коллективных операциях.
Структура проста. Вы запускаете N процессов (один на GPU, потенциально на нескольких машинах). Каждый процесс инициализирует группу процессов — канал коммуникации, поддерживаемый NCCL (NVIDIA Collective Communications Library) для передач между GPU. Каждый процесс получает три номера идентификации: его глобальный ранг (уникален во всех машинах), его локальный ранг (уникален в его машине) и общий размер мира.
Каждый процесс содержит идентичную копию модели. Данные разделены между процессами с использованием DistributedSampler — каждый ранг видит другой срез набора данных, но веса модели остаются (и остаются) идентичными.
Критический механизм происходит во время backward(). DDP регистрирует хуки на каждом параметре. Когда вычисляется градиент для параметра, DDP группирует его с близлежащими градиентами и запускает операцию all-reduce по группе процессов. Эта all-reduce вычисляет средний градиент на всех рангах. Поскольку каждый ранг теперь имеет одинаковый усреднённый градиент, последующий шаг оптимизатора производит идентичные обновления весов, сохраняя все реплики в синхронизации — без любого явного синхронизационного кода с нашей стороны.
Вот почему DDP строго превосходит более старый DataParallel: нет узкого места одного основного GPU, нет избыточных прямых проходов, и коммуникация градиентов перекрывается с вычислением обратного прохода.
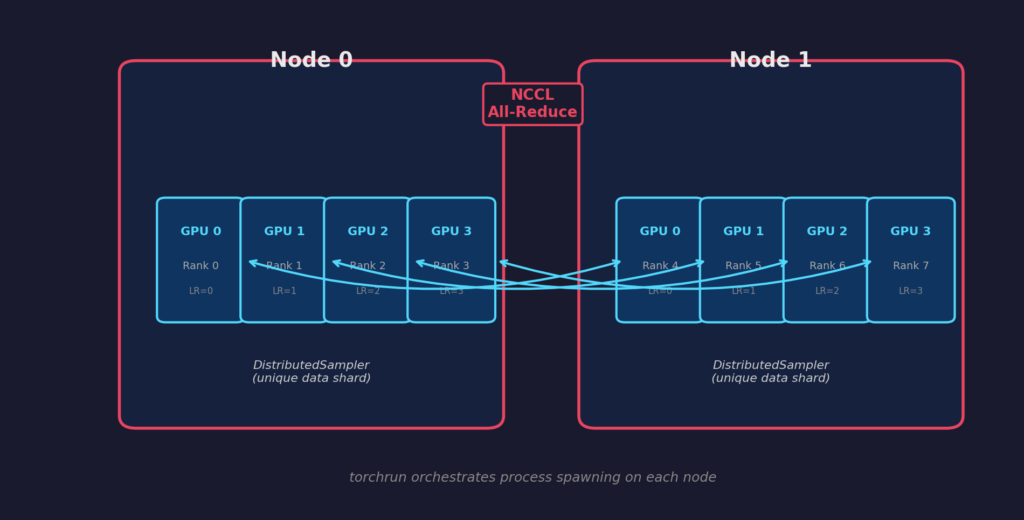
Рисунок 1: Поток синхронизации градиентов DDP. All-reduce происходит автоматически через хуки, зарегистрированные во время backward().
Ключевая терминология
| Термин | Значение |
|---|---|
| Ранг | Глобально уникальный ID процесса (от 0 до world_size – 1) |
| Локальный ранг | Индекс GPU на одной машине (от 0 до nproc_per_node – 1) |
| Размер мира | Общее число процессов на всех узлах |
| Группа процессов | Канал коммуникации (NCCL), соединяющий все ранги |
3. Обзор архитектуры
Production конвейер обучения никогда не должен быть одним монолитным скриптом. Наш разделён на шесть сосредоточенных модулей, каждый с одной ответственностью. График зависимостей ниже показывает, как они связаны — обратите внимание, что config.py находится внизу, действуя как единственный источник истины для каждого гиперпараметра.
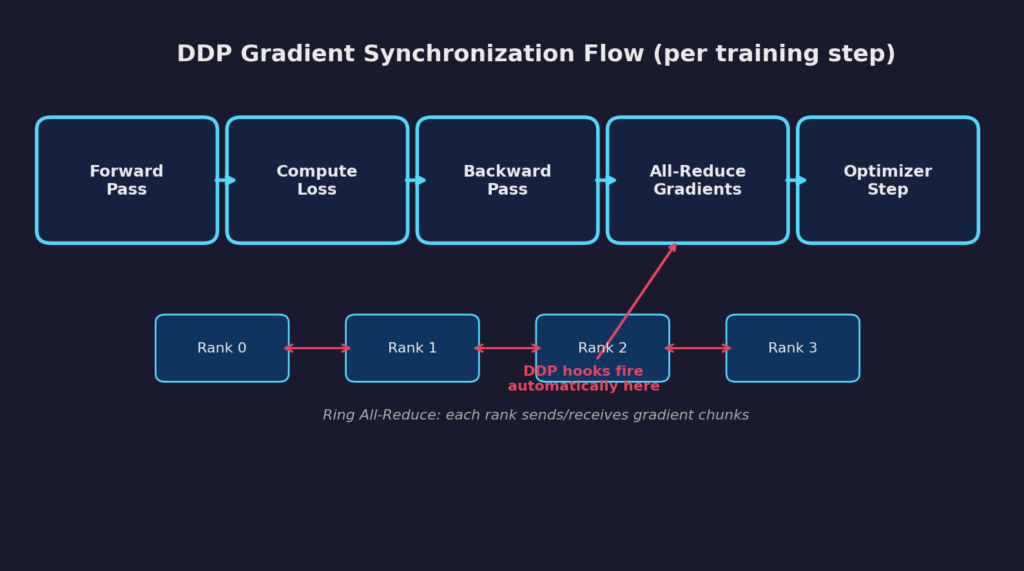
Рисунок 2: График зависимостей модулей. train.py координирует все остальные модули. config.py импортируется всеми
Вот структура проекта:
pytorch-multinode-ddp/
├── train.py # Точка входа — цикл обучения
├── config.py # Конфигурация dataclass + argparse
├── ddp_utils.py # Инициализация распределённого, очистка, сохранение контрольных точек
├── model.py # MiniResNet (облегчённый вариант ResNet)
├── dataset.py # Синтетический набор данных + загрузчик DistributedSampler
├── utils/
│ ├── logger.py # Структурированное логирование с учётом ранга
│ └── metrics.py # Скользящие средние + распределённый all-reduce
├── scripts/
│ └── launch.sh # Многоузловой обёртка torchrun
└── requirements.txt
Это разделение означает, что вы можете заменить реальный набор данных, отредактировав только dataset.py, или заменить модель, отредактировав только model.py. Цикл обучения никогда не нужно менять.
4. Централизованная конфигурация
Жёстко закодированные гиперпараметры — враг воспроизводимости. Мы используем Python dataclass как единый источник конфигурации. Каждый другой модуль импортирует TrainingConfig и читает из него — ничего не жёстко закодировано.
Dataclass удваивает нашего парсера CLI: метод from_args() анализирует имена и типы полей, автоматически создавая флаги argparse с значениями по умолчанию. Это означает, что вы получаете –batch_size 128 и –no-use_amp бесплатно, без написания единой строки парсера вручную.
@dataclass
class TrainingConfig:
"""Неизменяемый набор каждого параметра, необходимого конвейеру обучения."""
# Модель
num_classes: int = 10
in_channels: int = 3
image_size: int = 32
# Данные
batch_size: int = 64 # на GPU
num_workers: int = 4
# Оптимизатор / Планировщик
epochs: int = 10
lr: float = 0.01
momentum: float = 0.9
weight_decay: float = 1e-4
# Распределённые вычисления
backend: str = "nccl"
# Смешанная точность
use_amp: bool = True
# Накопление градиентов
grad_accum_steps: int = 1
# Сохранение контрольных точек
checkpoint_dir: str = "./checkpoints"
save_every: int = 1
resume_from: Optional[str] = None
# Логирование и профилирование
log_interval: int = 10
enable_profiling: bool = False
seed: int = 42
@classmethod
def from_args(cls) -> "TrainingConfig":
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
defaults = cls()
for name, val in vars(defaults).items():
arg_type = type(val) if val is not None else str
if isinstance(val, bool):
parser.add_argument(f"--{name}", default=val,
action=argparse.BooleanOptionalAction)
else:
parser.add_argument(f"--{name}", type=arg_type, default=val)
return cls(**vars(parser.parse_args()))
Почему dataclass вместо YAML или JSON? Три причины: (1) подсказки типов применяются IDE и mypy, (2) нет зависимости от сторонних библиотек конфигурации, и (3) каждый параметр имеет видимое значение по умолчанию рядом с его объявлением. Для production систем, которые нуждаются в иерархических конфигурациях, вы всегда можете наложить Hydra или OmegaConf поверх этого паттерна.
5. Управление распределённым жизненным циклом
Распределённый жизненный цикл имеет три фазы: инициализация, запуск и отключение. Ошибка в любой из них может привести к молчаливым зависаниям, поэтому мы оборачиваем всё в явную обработку ошибок.
Инициализация группы процессов
Функция setup_distributed() читает три переменные окружения, которые torchrun устанавливает автоматически (RANK, LOCAL_RANK, WORLD_SIZE), закрепляет правильный GPU с torch.cuda.set_device() и инициализирует группу процессов NCCL. Она возвращает замороженный dataclass — DistributedContext — который остальная кодовая база передаёт вместо повторного чтения os.environ.
@dataclass(frozen=True)
class DistributedContext:
"""Неизменяемый снимок распределённой идентичности текущего процесса."""
rank: int
local_rank: int
world_size: int
device: torch.device
def setup_distributed(config: TrainingConfig) -> DistributedContext:
required_vars = ("RANK", "LOCAL_RANK", "WORLD_SIZE")
missing = [v for v in required_vars if v not in os.environ]
if missing:
raise RuntimeError(
f"Отсутствующие переменные окружения: {missing}. "
"Запустите с torchrun или установите их вручную.")
if not torch.cuda.is_available():
raise RuntimeError(