Кеширование приглашений имеет смысл, потому что мы ожидаем, что системные приглашения и инструкции будут передаваться в качестве входных данных в LLM в точно таком же формате каждый раз. Но помимо этого, мы также можем ожидать, что пользовательские запросы будут повторяться или в некоторой степени выглядеть похожими. Особенно при развертывании RAG или других AI-приложений в организации, мы ожидаем, что большая часть запросов будет семантически похожа или даже идентична. Естественно, группы пользователей внутри организации обычно интересуются похожими вещами, такими как «сколько дней ежегодного отпуска имеет право получить сотрудник согласно политике отдела кадров» или «каков процесс подачи командировочных расходов». Тем не менее, статистически крайне маловероятно, что несколько пользователей зададут совершенно одинаковый запрос (одинаковые слова для точного совпадения), если только мы не предоставим им предложенные стандартизированные запросы в пользовательском интерфейсе приложения. Однако вполне вероятно, что пользователи задают запросы с разными словами, которые семантически очень похожи. Таким образом, имеет смысл подумать и о семантическом кеше помимо обычного кеша.
Таким образом, мы можем различить два типа кеша:
- Кеширование с точным совпадением — когда мы кешируем исходный текст или какую-то нормализованную версию его. Тогда мы попадаем в кеш только при точном, слово в слово совпадении текста. Кеширование с точным совпадением можно реализовать с помощью KV-кеша, например Redis.
- Семантическое кеширование — создание встраивания текста. Затем мы попадаем в кеш с любым текстом, который семантически похож на него и превышает предопределённый порог оценки сходства (например, косинусное сходство выше ~0,95). Поскольку нас интересует семантика текстов и мы выполняем поиск по сходству, нужно использовать векторную базу данных, например ChromaDB, в качестве хранилища кеша.
В отличие от кеширования приглашений, где мы используем кеш, встроенный в сервис API LLM, для реализации кеширования на других этапах RAG-конвейера нам нужно использовать внешнее хранилище кеша, такое как Redis или ChromaDB, упомянутые выше. Хотя это немного хлопотно, так как нам нужно самостоятельно настроить эти хранилища кеша, это также дает нам больше контроля над параметризацией кеша. Например, мы можем решить о политике истечения кеша, то есть о том, как долго кешированный элемент остается действительным и может быть переиспользован. Этот параметр памяти кеша определяется как Time-To-Live (TTL).
Как показано в предыдущих материалах, очень простой RAG-конвейер выглядит примерно так:
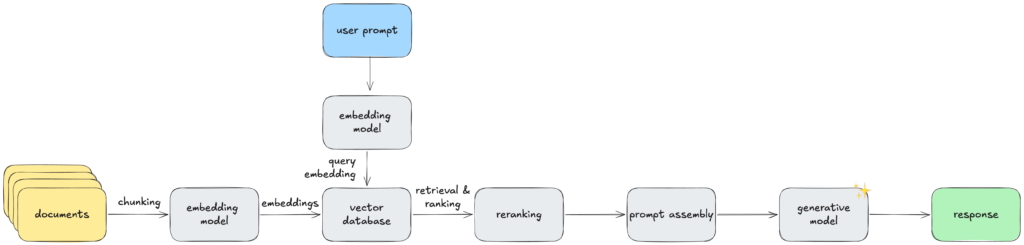
Даже в самой простой форме RAG-конвейера мы уже используем механизм, похожий на кеширование, даже не осознавая этого. То есть хранение встраиваний в векторной базе данных и их извлечение оттуда вместо того, чтобы каждый раз запрашивать модель встраивания и пересчитывать встраивания. Это очень просто и по сути является неотъемлемой частью даже очень простого RAG-конвейера, потому что встраивания документов обычно остаются неизменными (нам нужно пересчитать встраивание только когда документ базы знаний изменяется), поэтому имеет смысл вычислить один раз и сохранить его где-нибудь.
Но помимо хранения встраиваний базы знаний в векторной базе данных, другие части RAG-конвейера также могут быть переиспользованы, и мы можем получить пользу от применения кеширования к ним. Давайте посмотрим, что это такое более подробно!
1. Кеш встраиваний запроса
Первое, что происходит в RAG-системе при отправке запроса, это то, что запрос преобразуется в вектор встраивания, чтобы мы могли выполнить семантический поиск и извлечение в базе знаний. Очевидно, что этот шаг очень легкий в сравнении с вычислением встраиваний всей базы знаний. Тем не менее, в приложениях с высокой нагрузкой это может по-прежнему добавить ненужную задержку и стоимость, и в любом случае пересчитывать одни и те же встраивания для одних и тех же запросов снова и снова — это пустая трата.
Итак, вместо вычисления встраивания запроса каждый раз с нуля, мы можем сначала проверить, вычислили ли мы уже встраивание для того же запроса раньше. Если да, мы просто переиспользуем кешированный вектор. Если нет, мы генерируем встраивание один раз, сохраняем его в кеш и делаем доступным для будущего переиспользования.
В этом случае наш RAG-конвейер будет выглядеть примерно так:
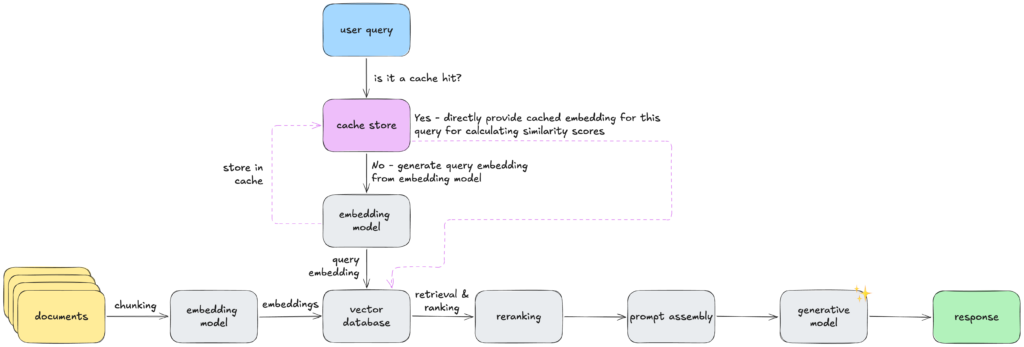
Самый простой способ реализовать кеширование встраивания запроса — это поиск точного совпадения исходного пользовательского запроса. Например:
What area codes correspond to Athens, Greece?Тем не менее, мы также можем использовать нормализованную версию исходного пользовательского запроса, выполнив некоторые простые операции, такие как преобразование в нижний регистр или удаление пунктуации. Таким образом, следующие запросы…
What area codes correspond to athens greece?
What area codes correspond to Athens, Greece
what area codes correspond to Athens // Greece?… будут все соответствовать …
what area codes correspond to athens greece?Мы затем ищем этот нормализованный запрос в KV-хранилище, и если мы получим попадание в кеш, мы можем затем напрямую использовать встраивание, которое хранится в кеше, без необходимости снова делать запрос к модели встраивания. Это будет встраивание, выглядящее примерно так, например:
[0.12, -0.33, 0.88, ...]В целом, для кеша встраивания запроса ключи-значения имеют следующий формат:
query → embeddingКак вы можете уже себе представить, количество попаданий для этого может значительно улучшиться, если мы предложим пользователям стандартизированные запросы в пользовательском интерфейсе приложения, помимо того, чтобы позволить им вводить свои собственные запросы в свободном тексте.
2. Кеш извлечения
Кеширование также может быть использовано на этапе извлечения RAG-конвейера. Это означает, что мы можем кешировать извлеченные результаты для конкретного запроса и минимизировать необходимость выполнения полного извлечения для похожих запросов. В этом случае ключом кеша может быть исходный или нормализованный пользовательский запрос или встраивание запроса. Значение, которое мы получаем обратно из кеша, — это извлеченные фрагменты документов. Итак, наш RAG-конвейер с кешированием извлечения, либо с точным совпадением, либо с семантическим, будет выглядеть примерно так:
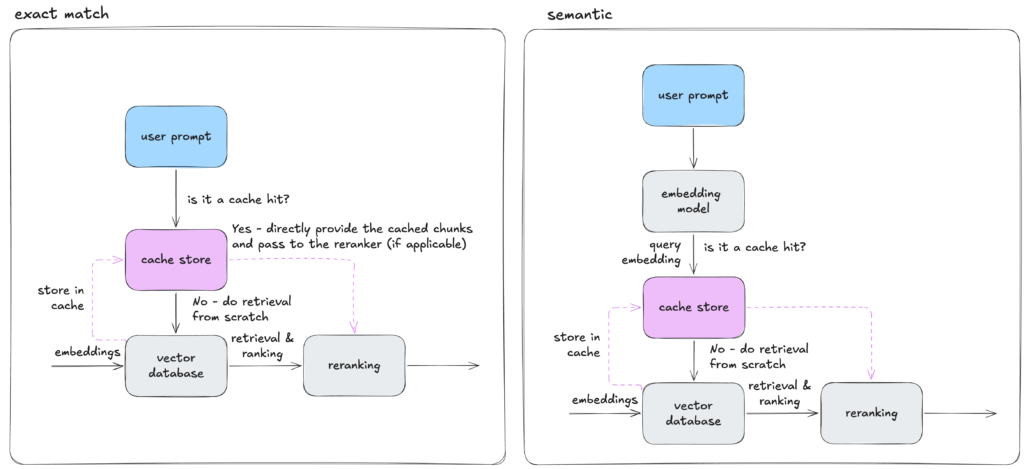
Итак, для нашего нормализованного запроса…
what area codes correspond to athens greece?или из встраивания запроса…
[0.12, -0.33, 0.88, ...]мы напрямую получим из кеша извлеченные фрагменты.
[
chunk_12,
chunk_98,
chunk_42
]Таким образом, когда отправляется идентичный или даже несколько похожий запрос, мы уже имеем соответствующие фрагменты и документы в кеше — нет необходимости выполнять шаг извлечения. Другими словами, даже для запросов, которые только умеренно похожи (например, косинусное сходство выше ~0,85), точный ответ может не существовать в кеше, но соответствующие фрагменты и документы, необходимые для ответа на запрос, часто существуют.
В целом, для кеша извлечения ключи-значения имеют следующий формат:
query → retrieved_chunksМожно задаться вопросом, чем это отличается от кеша встраивания запроса. Ведь если запрос одинаков, почему бы не напрямую попасть в кеш в кеше извлечения?