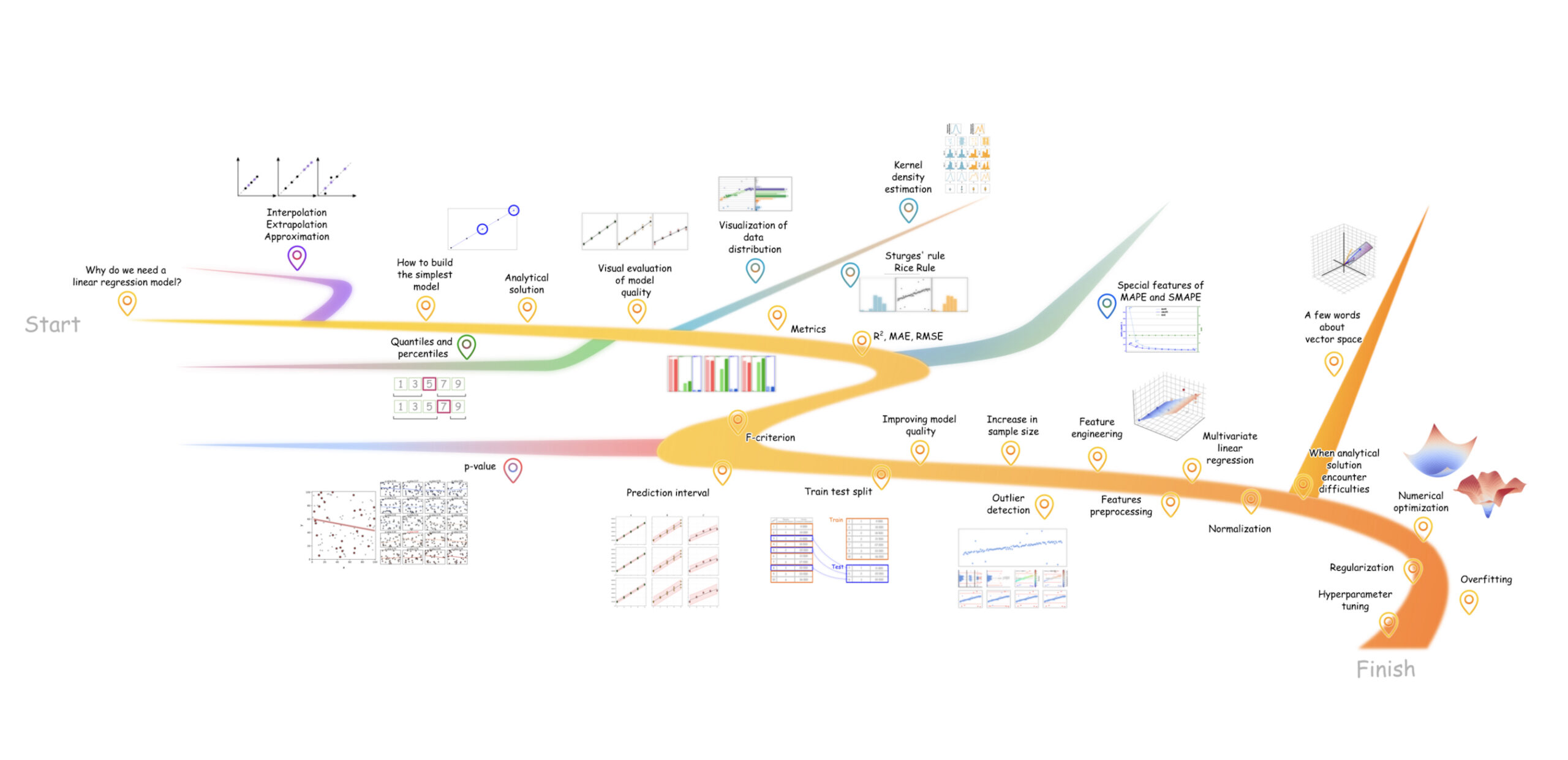
Дорожная карта статьи с опциональными боковыми путями. Цвета дорог соответствуют цветам рамок фигур в соответствующих разделах. Графики из основного повествования используют градиент рамки от оранжевого к красному и так далее (изображение автора)
Привет, люди из Towards Data Science! Если вы когда-либо хотели понять, как работает линейная регрессия, или просто освежить основные идеи, не прыгая между множеством разных источников — эта статья для вас. Это очень длинное чтение, на написание которого у меня ушло более года. Оно построено вокруг пяти ключевых идей:
- Визуалы в первую очередь. Это статья в стиле комиксов: чтение текста помогает, но не требуется. Быстрый просмотр изображений и анимаций может дать вам прочное понимание того, как все работает. Всего более 100 визуалов;
- Анимации там, где они могут помочь (всего 33). Информатика лучше всего понимается в движении, поэтому я использую анимации для объяснения ключевых идей;
- Удобство для начинающих. Я сделал материал максимально простым, чтобы статью было легко читать новичкам;
- Воспроизводимость. Большинство визуалов были созданы на Python, и код открыт;
- Фокус на практику. Каждый следующий шаг решает проблему, которая возникает на предыдущем шаге, так что вся статья остается связанной.
Еще одно: статья намеренно упрощена, поэтому некоторые формулировки и примеры могут быть немного грубыми или не совсем точными. Не просто верьте мне на слово — думайте критически и перепроверьте мои утверждения. Для наиболее важных частей я предоставляю ссылки на исходный код, чтобы вы могли все проверить сами.
Содержание
- Для кого эта статья
- Что охватывает эта статья
- Краткий литературный обзор
- Хорошая модель начинается с данных
- Зачем нам нужна модель?
- Как построить простую модель
- Почему это уравнение и почему два коэффициента
- Аналитическое решение
- Ошибка также является частью модели
- Как измерить качество модели
- Визуальная оценка
- Метрики
- F-тест
- Неопределенность прогноза. Интервал предсказания
- Разделение на обучающую и тестовую выборки и метрики
- Представьте, что в мире всего 45 квартир…
- Улучшение качества модели
- Расширение выборки
- Сокращение выборки путем фильтрации выбросов
- Усложнение модели: множественная линейная регрессия
- Инженерия признаков. Генерирование новых признаков
- Сбор новых признаков
- Замечание о визуализации
- О важности предварительной обработки (категориальных) признаков
- Оценка важности признаков
- Нормализация и стандартизация (стандартное масштабирование) признаков
- Коэффициент модели и ландшафт ошибок при стандартизированных признаках
- Расширение аналитического решения на многомерный случай
- Когда аналитическое решение встречает трудности
- Численные методы
- Исчерпывающий поиск
- Случайный поиск
- Использование информации о направлении
- Градиентный спуск
- Регуляризация
- Переобучение
- Настройка гиперпараметров
- Линейная регрессия — это целый мир
- Заключение
Для кого эта статья
Пропустите этот абзац, просто прокрутите статью в течение двух минут и посмотрите на визуалы. Вы сразу поймете, хотите ли вы прочитать ее подробнее (основные идеи показаны в графиках и анимациях). Эта статья предназначена для начинающих и для всех, кто работает с данными — а также для опытных людей, которые хотят быстро освежить знания.
Что охватывает эта статья
Статья структурирована в три акта:
- Линейная регрессия: что это такое, почему мы ее используем и как подогнать модель;
- Как оценить производительность модели;
- Как улучшить модель, когда результаты недостаточно хороши.
На высоком уровне эта статья охватывает:
- моделирование на основе данных;
- аналитическое решение для линейной регрессии и почему оно не всегда практично;
- способы оценки качества модели, как визуально, так и с помощью метрик;
- множественную линейную регрессию, где предсказания основаны на многих признаках;
- вероятностную сторону линейной регрессии, поскольку предсказания не точны и важно количественно оценить неопределенность;
- способы улучшения качества модели, от добавления сложности до упрощения модели с помощью регуляризации.
Более конкретно, в статье рассматриваются:
- метод наименьших квадратов для простой линейной регрессии;
- метрики регрессии такие как R², RMSE, MAE, MAPE, SMAPE, а также коэффициент корреляции Пирсона и коэффициент детерминации, плюс визуальная диагностика, например графики остатков;
- максимальное правдоподобие и интервалы предсказания;
- разделение на обучающую/тестовую выборки, почему это важно и как это делать;
- методы обработки выбросов, включая RANSAC, расстояние Махаланобиса, локальный фактор выбросов (LOF) и расстояние Кука;
- предварительная обработка данных, включая нормализацию, стандартизацию и кодирование категориальных признаков;
- линейную алгебру за методом наименьших квадратов и как он распространяется на многомерную регрессию;
- численные методы оптимизации, включая градиентный спуск;
- L1 и L2 регуляризацию для линейных моделей;
- кросс-валидацию и оптимизацию гиперпараметров.
Хотя эта статья сосредоточена на линейной регрессии, некоторые части — особенно раздел об оценке модели — применимы к другим алгоритмам регрессии. То же самое относится к разделу о выборе модели.