Анализ выживаемости [AВ] — это раздел статистики, используемый для прогнозирования количества времени, необходимого для возникновения определенного события.[1]
Также известный как Time-to-event, этот метод анализа может определить, сколько времени потребуется для наступления события, учитывая при этом тот факт, что к моменту сбора данных некоторые события еще не произошли.
Примеры применения анализа выживаемости найдутся не только в медицине и биологии, но везде:
- Время до отказа машины
- Время до отмены подписки клиентом
- Время до повторной покупки клиентом
Поскольку мы пытаемся оценить число, а не группу или класс, это означает, что мы имеем дело с типом регрессионной задачи. Тогда почему нельзя использовать линейную регрессию OLS?
Почему использовать анализ выживаемости?
Стандартные регрессионные модели, такие как OLS или логистическая регрессия, плохо справляются с данными выживаемости, поскольку они предназначены для обработки завершенных событий, а не «текущих» историй.
Представьте, что вы хотите предсказать, кто завершит десятимильную гонку, но входные данные — это событие, которое еще происходит. Гонка находится на отметке 2 часа, и вы хотите использовать имеющиеся данные для оценки чего-либо.
Обычные алгоритмы регрессии откажут, потому что:
- OLS: у вас есть только данные от тех, кто уже финишировал. Использование только их данных создаст огромное смещение в пользу более быстрых людей.
- Логистическая регрессия: она может сказать, финишировал ли кто-то в гонке, вероятно, но она одинаково относится к тем, кто финишировал за 30 минут, и к тем, кто финишировал за 8 часов.
Основы анализа выживаемости
Давайте разберемся с несколькими важными концепциями для понимания анализа выживаемости.
Во-первых, мы должны понять рождение и смерть точки данных.
- Рождение: момент, когда мы начали измерять эту точку данных. Например, день диагностики рака у пациента или день найма сотрудника в компанию. Обратите внимание, что наблюдения не обязательно начинаются в одно и то же время.
- Смерть: наступает при возникновении события интереса. День, когда сотрудник покинул компанию.
Интересная особенность АВ состоит в том, что исследование или наблюдение могут закончиться до наступления события. В этом случае у нас будет еще одна важная концепция: цензурированная точка данных.
- Цензурирование (Non-death): если исследование заканчивается или испытуемый выбывает раньше наступления события, данные «цензурируются», что означает, что мы знаем только, что они выжили как минимум до этого момента.
Данные могут быть цензурированы по-разному.
- Правое цензурирование: наиболее распространено. Событие происходит после окончания периода наблюдения или выбытия субъекта.
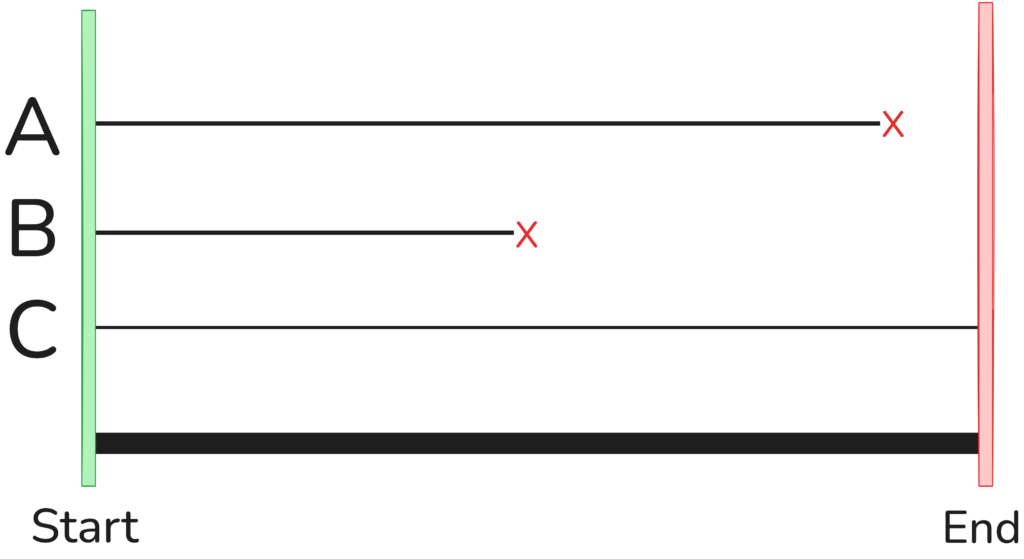
- Левое цензурирование: событие произошло до начала исследования.
Важно отметить, что анализ выживаемости — это способ оценить вероятность наступления события как функцию времени. Рассматривая выживаемость как функцию времени, мы можем ответить на вопросы, на которые не может ответить одна вероятность: «В каком конкретном месяце риск оттока клиента достигает пика?»
Теперь, когда мы знаем основы, давайте узнаем больше о функциях, используемых в АВ.
Функция выживаемости
Функция выживаемости S(t) выражает вероятность того, что событие не произойдет как функцию времени. Она естественно уменьшается по мере прохождения времени, так как все больше и больше людей будут испытывать событие.
Применяя это к нашему примеру текучести сотрудников, мы увидим вероятность того, что сотрудник остается в компании после N лет.
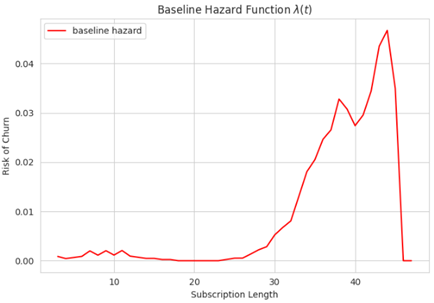
Функция опасности
Функция опасности указывает на вероятность наступления события в заданный момент времени. Это противоположность функции выживаемости и представляет риск оттока (вместо вероятности остаться в компании).
Эта функция вычислит вероятность того, что сотрудники, которые не уволились до этого момента, сделают это с этого момента времени.
Выбор модели для анализа выживаемости
Как видите, АВ — это тема, которая может быстро стать глубокой и сложной. Но давайте постараемся сделать это просто.
Есть две основные модели, используемые при проведении анализа выживаемости. Одна — это Каплан-Майер, которая проще, но не учитывает влияние дополнительных переменных-предикторов и требует некоторых предположений.
Другая — это модель пропорциональных рисков Кокса, которая является отраслевым стандартом, потому что может учитывать другие переменные в модели, математически более стабильна и хорошо работает, даже если некоторые предположения нарушены.
Давайте узнаем о них больше.
Каплан-Майер
- Хорошо работает с правоцензурированными данными (помните? когда событие происходит после окончания периода наблюдения)
- Интуитивная модель
- Непараметрическая: не следует никакому распределению
- Требуются предположения, такие как: отсев не связан с событием; время входа не влияет на риск выживания; времена событий известны точно.
- Возвращает функцию выживаемости, которая выглядит как лестница
Когда использовать:
- Простой анализ выживаемости без других ковариат или предикторов.
- Отлично подходит для быстрых визуализаций.
Пропорциональные риски Кокса
- Отраслевой стандарт
- Принимает дополнительные предикторы или ковариаты
- Хорошо работает, даже если некоторые предположения нарушены
- Оценивает функцию опасности, которая, как правило, более стабильна, чем функции выживаемости
Когда использовать:
- Оценка на данных с несколькими переменными-предикторами (ковариатами).
Далее давайте приступим к коду.
Код
В этом разделе мы узнаем, как моделировать АВ с использованием обеих ранее представленных моделей.
Набор данных, выбранный для этого упражнения, — это Telco Customer Churn, который вы можете найти в репозитории UCI Machine Learning Repository под лицензией Creative Commons.

Далее давайте импортируем необходимые пакеты.
# Data
from ucimlrepo import fetch_ucirepo
# Data Wrangling
import pandas as pd
import numpy as np
# DataViz
import matplotlib.pyplot as plt
import seaborn as sns
# Lifelines Survival Analysis
from lifelines import KaplanMeierFitter
from lifelines import CoxPHFitter
# fetch dataset
telco_churn = fetch_ucirepo(id=563)
# data (as pandas dataframes)
X = telco_churn.data.features
y = telco_churn.data.targets
# Pandas df
df = pd.concat([X, y], axis=1)
df.head(3)Реализация Каплана-Майера
Как упоминалось, модель Каплана-Майера [КМ] очень простая и прямолинейная в использовании, что делает ее хорошим выбором для визуализации. Все, что нам нужно, — это две переменные: один предиктор и один ярлык.
Затем мы можем создать экземпляр модели КМ и обучить ее на данных, используя Subscription Length (общее количество месяцев подписки) в качестве предиктора и Churn в качестве наблюдаемого события.
# Instantiate K-M
kmf = KaplanMeierFitter()
# Fit the model
kmf.fit(df['Subscription Length'],
event_observed=df['Churn'],
label= 'Customer Churn')Готово. Далее мы можем визуализировать функцию выживаемости.
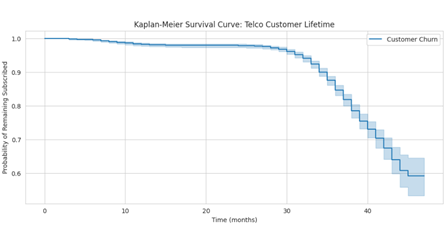
# Plot survival curve
plt.figure(figsize=(12, 5))
kmf.plot_survival_function()
plt.title('Kaplan-Meier Survival Curve: Telco Customer Lifetime')
plt.xlabel('Time (months)')
plt.ylabel('Probability of Remaining Subscribed')
plt.grid(True)
plt.show()Это замечательно! Мы видим, что более 90% клиентов остаются в телекоммуникационной компании примерно на 35 месяцев.
