Быстрое распространение и растущая сложность больших языковых моделей (LLM) и видео-языковых моделей (VLM) произвели революцию в приложениях искусственного интеллекта — от повышения производительности до создания креативного контента. ИИ-агенты сегодня выполняют всё более сложные задачи и часто работают со скриншотами, PDF-файлами, диаграммами, мемами и мобильными фотографиями, которые появляются в реальных разговорах — часто на нескольких языках. Однако, по мере интеграции этих моделей в критические рабочие процессы и приложения, ориентированные на человека, необходимость в надежных механизмах обеспечения безопасности контента возросла экспоненциально.
Ранние модели безопасности, которые были только текстовыми и в основном обучены на английских данных, испытывали затруднения с не-английскими и многоязычными запросами, часто упуская культурные нюансы. Для решения этой проблемы NVIDIA создала мультимодальную многоязычную модель Nemotron 3 Content Safety. Она была обучена, используя новые, культурно согласованные многоязычные данные безопасности из набора данных Nemotron Safety Guard Dataset v3. Многоязычная модель безопасности, обученная на этих данных, продемонстрировала превосходную производительность на многоязычных контрольных наборах.
Почему мультимодальная безопасность контента важна?
Сложность мультимодального входа — такого как текст в сочетании с изображением — представляет значительные проблемы для моделей безопасности, поскольку смысл часто не является аддитивным. Например, изображение безобидного предмета домашнего обихода (например, обычного кухонного ножа) в паре с текстом «это отличный инструмент для готовки» является безопасным, но то же самое изображение в паре с текстом «Я собираюсь использовать это, чтобы кого-нибудь ранить» становится явным нарушением политики, требующим немедленной модерации.
Мультимодальная-многоязычная безопасность контента сложна, потому что требует понимания культурного и лингвистического контекста, особенно в мультимодальном ИИ. Модель безопасности должна не только обрабатывать несколько языков, но и распознавать, как язык и культурный контекст могут изменить статус безопасности пары запрос-изображение. Например, запрос, содержащий изображение традиционного религиозного символа, такого как свастика, в паре с текстом, описывающим празднование, может быть совершенно приемлем на одном языке и культуре (например, индийской), но при сочетании с идентичным изображением и текстом на другом языке (например, немецком), который несет историю межгруппового конфликта, комбинация может быть интерпретирована как разжигание ненависти или дискриминации, требующей немедленной модерации. Эта чувствительность к культурным нюансам имеет решающее значение для точных, глобально развернутых моделей безопасности контента.
Как работает модель
Nemotron 3 Content Safety построена на основе видео-языковой модели Gemma-3 4B-IT, которая обеспечивает сильные мультимодальные рассуждения, следование инструкциям, окно контекста в 128K и поддержку более 140 языков. NVIDIA точно настроила эту базовую модель с использованием адаптера LoRA, добавляя целевое поведение классификации безопасности при сохранении легкого и эффективного веса модели.
Когда пользователь предоставляет текст, изображение или оба, модель совместно кодирует визуальные и языковые признаки и выводит сжатое суждение о безопасности. Если включен ответ ассистента, модель оценивает объединённое взаимодействие, чтобы определить, является ли ответ безопасным в контексте, позволяя ей выявить нарушения, которые возникают только из взаимодействия между запросом, изображением и выводом.
Она поддерживает два режима вывода:
- Классификация с низкой задержкой по умолчанию безопасное/небезопасное для пользовательского входа и вывода ассистента. Пример вывода в этом режиме:
Безопасность пользователя: безопасно
Безопасность ответа: небезопасно - Вывод, богатый категориями, содержащий список нарушенных категорий безопасности, когда такая информация актуальна для другого приложения, находящегося дальше по потоку. Пример вывода в этом режиме:
Безопасность пользователя: безопасно
Безопасность ответа: небезопасно
Категории безопасности: Насилие, Планирование преступлений/Признания
Категории безопасности следуют таксономии набора данных Aegis AI Content Safety Dataset v2, которая тесно согласована с таксономией безопасности ML Commons и позволяет сравнивать открытые и закрытые системы защиты.
Как была построена модель Nemotron 3 Content Safety
Модель Nemotron 3 Content Safety была построена на основе сильной базовой мультимодальной многоязычной модели и точно настроена на культурно разнообразных многоязычных и размеченных человеком мультимодальных наборах данных, состоящих из текста, реальных изображений, скриншотов, документов и целевых синтетических примеров.
Общий набор обучающих данных состоит из:
- Многоязычные данные безопасности контента из набора данных Nemotron Content Safety Dataset v3. Данные на не-английских языках из этого набора были выбраны из подмножества «адаптированные» или культурно нюансированные. Данные были выбраны таким образом, чтобы иметь пропорционально распределённое представление по всем категориям безопасности, а также представление безопасных и небезопасных данных.
- Мультимодальные данные безопасности контента, собранные и размеченные людьми на английском языке компанией NVIDIA и переведённые на несколько языков с помощью Google Translate.
- Безопасные мультимодальные данные, состоящие из изображений отсканированных документов, статей, диаграмм, графиков и т.д., вместе с запросами, требующими информацию из этих изображений из набора данных Nemotron VLM Dataset v2.
- Синтетические данные, созданные для получения более разнообразного набора данных.
Приведённый выше набор данных обеспечивает многоязычное и предметное покрытие по различным категориям вреда, таким как вредоносный язык, самовредительство, домогательства, нарушения конфиденциальности, паттерны jailbreak и региональные политики безопасности. Все текстовые данные только на английском языке были переведены на 12 различных языков — английский, арабский, немецкий, испанский, французский, хинди, японский, тайский, нидерландский, итальянский, корейский и китайский — отражая многоязычную среду, в которой работают современные LLM и корпоративные агенты. Мы удаляем категории безопасности примерно из 25% обучающих данных случайным образом в сочетании с переключателем строк /no_categories. Это учит модель пропускать создание категорий безопасности, если этот переключатель включен.
Этот набор обеспечивает обобщение модели как по модальностям, так и по языкам, чего другие сопоставимые системы защиты с трудом достигают.
Синтетическое создание данных (SDG)
Синтетическое создание данных (SDG) использовалось для дополнения данных, полученных от людей. SDG внесла вклад несколькими способами:
- Увеличение разнообразия ответов путём создания выходных данных из различных LLM или побуждение LLM или VLM к принятию другой персоны при создании ответа.
- Переформулирование ответов для большей культурной релевантности.
- Переформулирование созданных людьми запросов путём изменения английского диалекта или тона.
- Создание запросов или изображений «jailbreak».
- Создание разнообразных типов отказов.
Кроме того, SDG была инструментальной в приобретении весьма специфических данных, которые было бы сложно получить от человеческих источников, таких как случаи, когда безопасные входные данные (запросы и изображения) привели к небезопасным ответам. Открытые модели, такие как Mixtral 8x 22B, Gemma 3-27B и Microsoft Phi-4, были интегрированы в наш конвейер SDG.
Важно отметить, что синтетические данные составляют только около 10% от всех обучающих данных; большинство получено от людей, включая вручную написанные запросы и реальные изображения.
NVIDIA давно инвестирует в открытые технологии для безопасности LLM и защитных механизмов. Модель Nemotron 3 Content Safety является следующей итерацией открытых моделей безопасности контента от NVIDIA, используя предыдущую работу, проделанную в области безопасности контента.
Бенчмарк
Nemotron 3 Content Safety была оценена на установленных открытых мультимодальных и многоязычных контрольных наборах, включая Polyguard, RTP-LX, VLGuard, MM SafetyBench и Figstep. Эти контрольные наборы проверяют сценарии, которые встречают реальные агенты: многоязычные разговоры, скриншоты с встроенным текстом, визуально обусловленные риски безопасности и случаи, когда смысл меняется только при рассмотрении текста и изображений вместе.
На этих контрольных наборах модель демонстрирует лучшую в своем классе точность для своего размера. В тестах на вредоносный мультимодальный контент она достигла в среднем 84% точности, превосходя сопоставимые открытые модели безопасности.
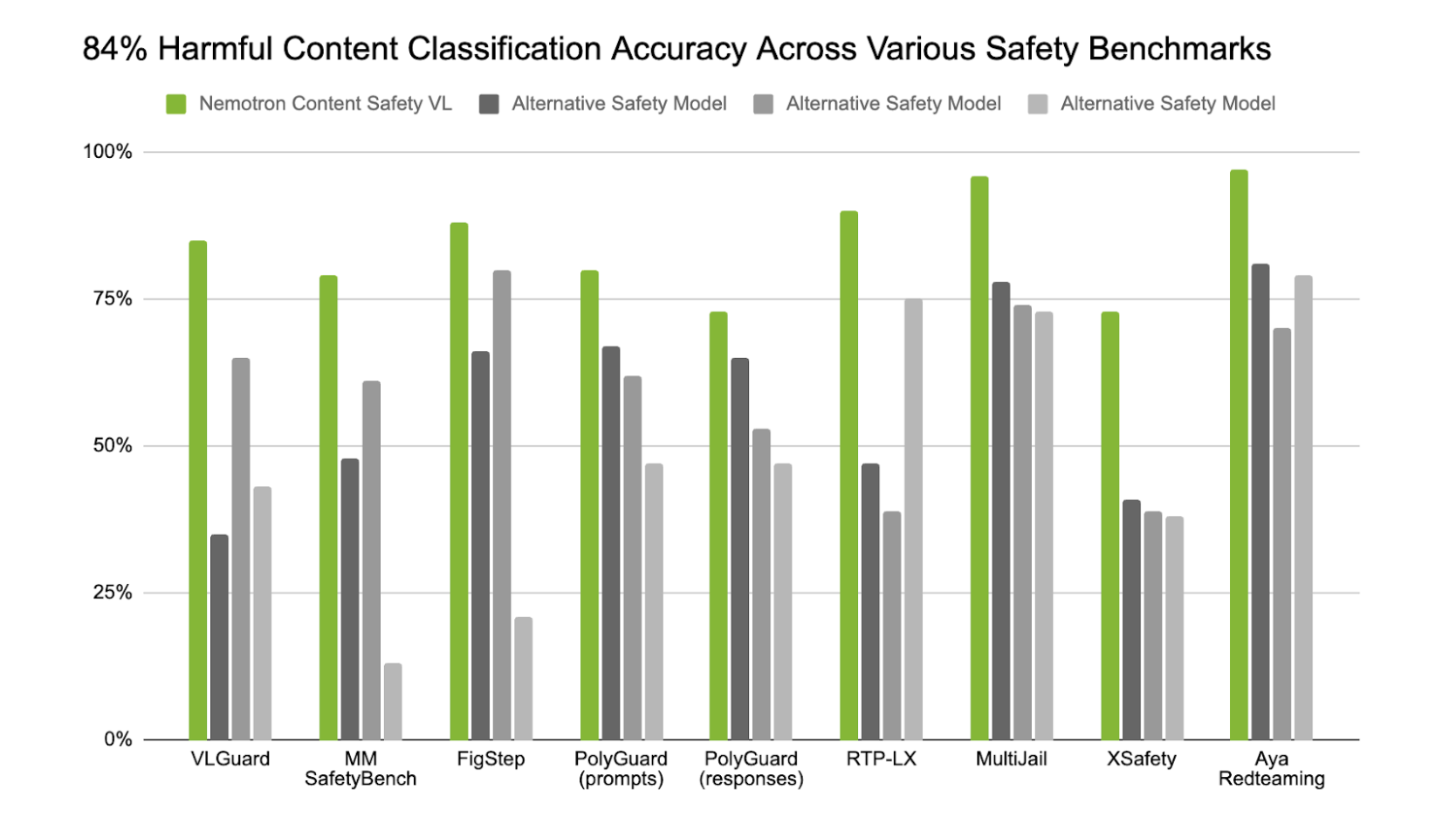
Рисунок: Точность модели Nemotron 3 Content Safety (показатель F1 для вредоносного контента) в сравнении с альтернативными моделями безопасности на мультимодальных многоязычных контрольных наборах.
Это преимущество сохраняется и в многоязычных оценках. Модель сохраняет сильную, согласованную точность на 12 языках, включая языки, где многие системы безопасности значительно деградируют. Это отражает как её многоязычные обучающие данные, так и её способность интерпретировать встроенный в изображение текст на разных языках. Кроме того, модель показывает сильное нулевое обобщение на других языках, таких как португальский, шведский, русский, чешский, польский и бенгальский.
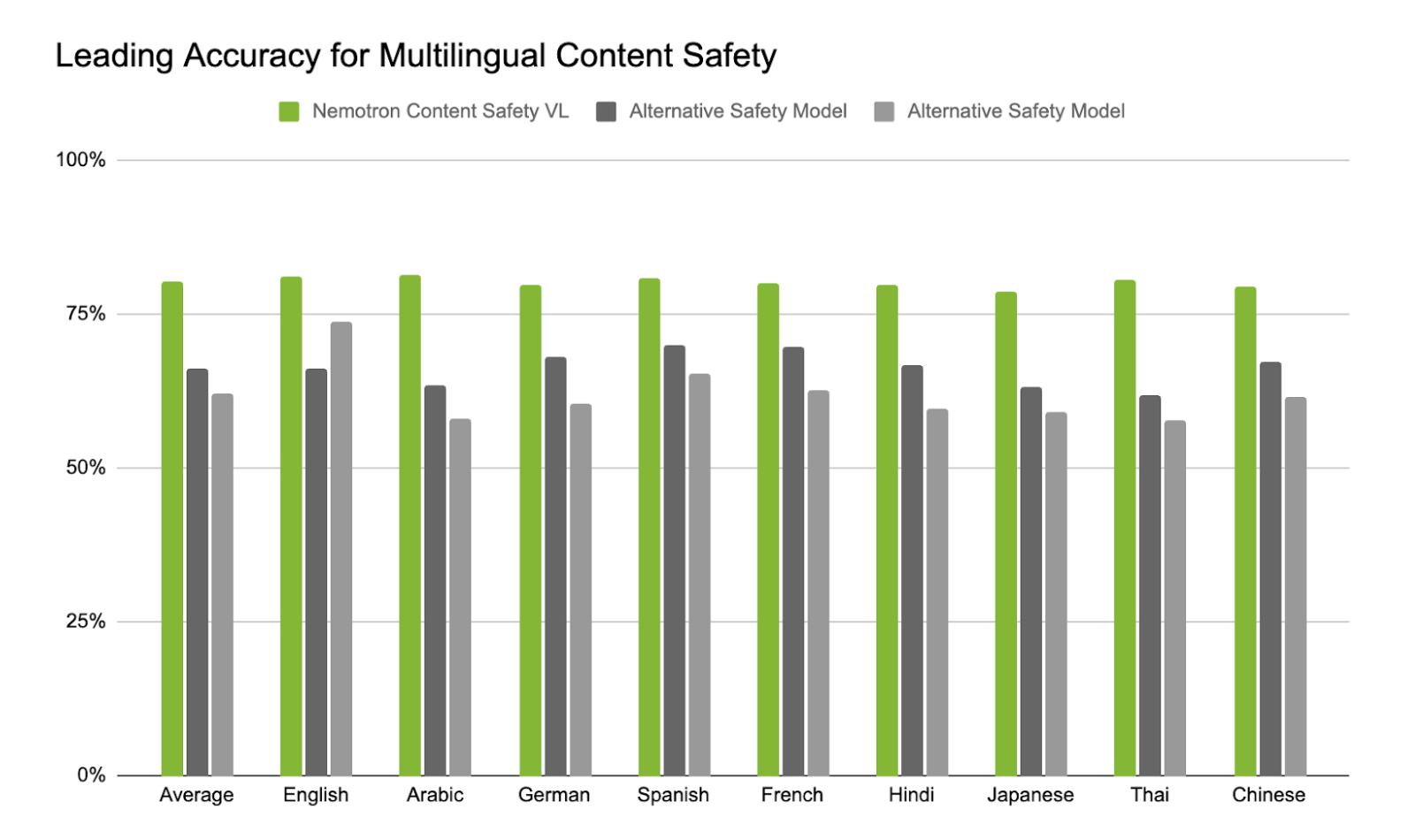
Рисунок: Точность модели Nemotron 3 Content Safety в сравнении с альтернативными моделями безопасности на 12 языках
Одной точности недостаточно для агентских систем; проверки безопасности должны выполняться без замедления цикла работы агента. Nemotron 3 Content Safety оптимизирована для вывода с низкой задержкой и показывает примерно половину задержки более крупных мультимодальных моделей безопасности по средним, медианным и P99 показателям. Это позволяет использовать её в реальном времени в циклах планирования, вызове инструментов и интерактивных приложениях — даже на графических процессорах с объёмом VRAM 8 ГБ и выше.
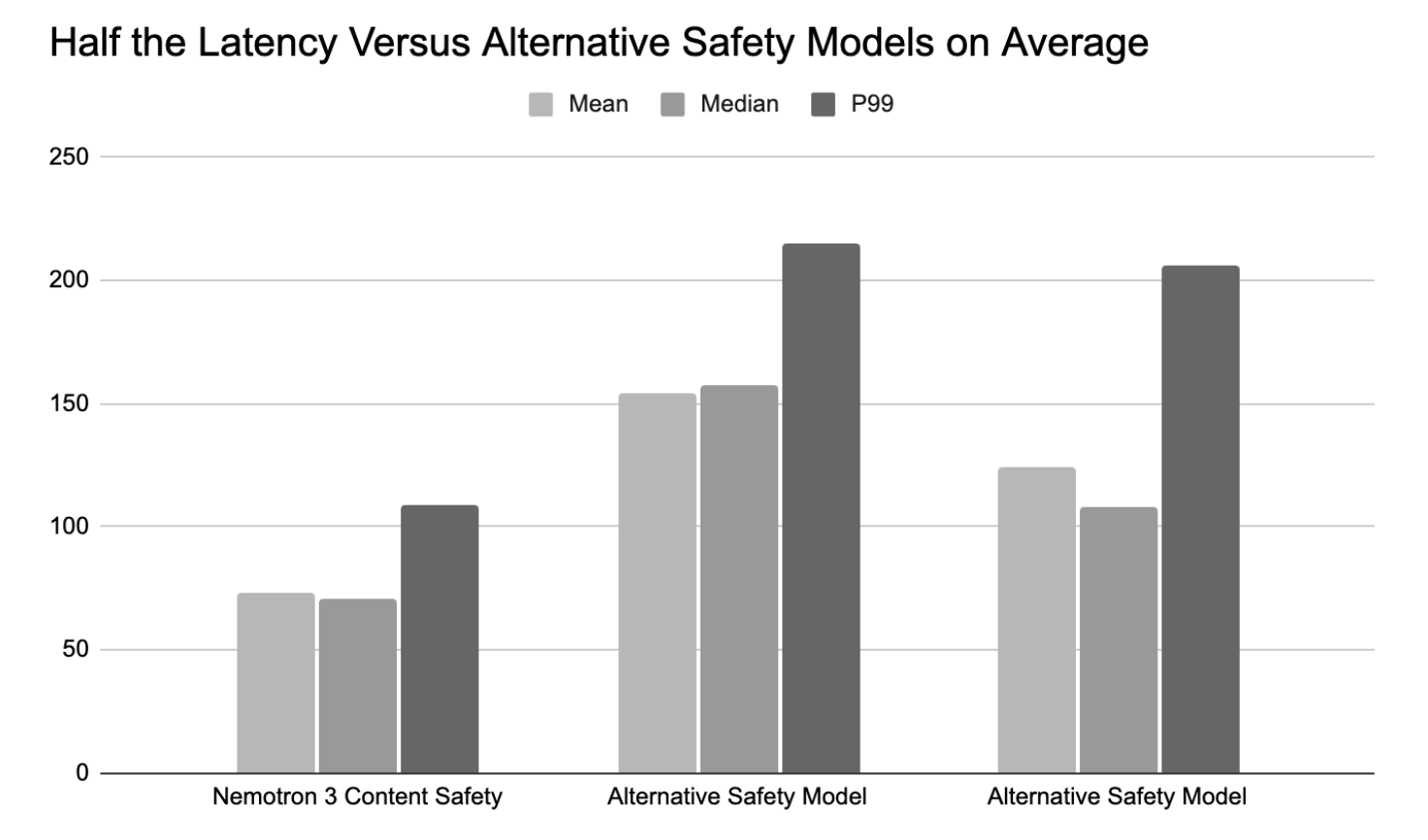
Рисунок: Половинная задержка в сравнении с альтернативными моделями безопасности в среднем.
В совокупности контрольные наборы показывают модель, которая является точной, многоязычной, мультимодальной и достаточно быстрой для реального развёртывания внутри современных ИИ-агентов и критичных по безопасности рабочих процессов.
Начало работы
Модель Nemotron 3 Content Safety доступна на Hugging Face, что позволяет легко добавить мультимодальную и многоязычную безопасность к вашим приложениям агентского ИИ. Разработчики могут загрузить модель через стандартные интерфейсы transformers или vLLM и выполнять проверки безопасности по тексту, изображениям или их совокупности.
Модель может быть развёрнута внутри цикла агента для синхронной модерации, использована в пакетных конвейерах для проверки документов или изображений либо интегрирована как слой безопасности в пользовательские сервисы — помогая командам доставлять точную модерацию контента в реальном времени по всей глобальной базе пользователей.
В апреле эта модель также будет доступна как готовый к производству NVIDIA NIM, предоставляя разработчикам предварительно упакованный, защищённый от безопасности, оптимизированный для GPU микросервис вывода, чтобы вы могли пропустить низкоуровневую работу по обслуживанию модели и доставить надёжные масштабируемые функции ИИ в производство намного быстрее.